【数据处理】做临床试验时,经常碰到数据缺失,怎么办?
科研论文时间
相信很多朋友都经历过临床数据缺失,看着一个个空白的格子束手无策。
其实在临床试验中,病例脱落导致数据缺失是十分常见且难以避免的。在尽量避免不必要的数据缺失的同时,还应掌握了相应的缺失数据处理方法。
一、为什么会产生「缺失数据」?
-
临床试验中的缺失数据一般是由于受试对象在试验中因依从性差、不良事件或疗效不佳等原因提前退出试验造成的; -
也可能是因为采集标本或测量过程中因样本量不足或灵敏度不够所造成的疗效指标缺失; -
也可能是在数据记录或整理过程中造成的数据丢失等。
二、缺失数据有哪些类型?
1. 完全随机缺失(missing completely at random,MCAR)
是指缺失数据的产生完全独立于可观察到和不可观察到的数据,其发生的比例不会依赖于受试者的特点,理论上不会给试验结果带来偏倚,数据分析时可仅分析现存数据。
例:因受试者搬家或出差等所造成的失访脱落。
2. 随机缺失(missing at random,MAR)
是指缺失数据的产生独立于不可观察到的数据,但会与可观察的数据有关。
受试者在试验中因不良事件或因疗效不佳而脱落,而不良事件发生和疗效不佳并不是完全随机发生,可能与其他因素相关,这些可观察到的因素包括反应变量以及性别、年龄等协变量,数据分析时应注意其间的相关性。
例:药物对男性疗效不佳、对年老患者疗效不佳、女性患者更易出现并发症等。
3. 非随机缺失(missing not at random,MNAR)
是指缺失数据的产生不仅与已观察的数据有关,还可能与某些不可观察的或未知的数据有关。
受试者意外死亡、因其他原因造成的身体健康问题造成的脱落均属于这一类型。
统计分析时没有很好的处理办法,或假定没有非随机缺失,或进行敏感性分析探讨缺失数据对结果的影响,往往要根据数据缺失过程的概率分布来考虑数据观测过程和缺失过程的联合概率分布,较为繁琐。
例:吸烟调查中,吸烟的患者可能更倾向于不直接作答;高收入人群不填写收入等。
三、如何处理缺失数据?
1. 直接剔除法:
当脱落病例所占比例很小,且属于 MCARZ(完全随机缺失),可以考虑直接剔除脱落病例产生的缺失记录,形成一个新的完全数据集,仅对现有的记录完整的数据进行统计分析。
例:有一次患者因车辆限号没来随访,可直接删除该次记录。
2. 前一次观察数据向后结转(last observation carried forward,LOCF):
将缺失数据前一次的观测值直接拿来进行替代填补, 方法虽简单, 但是严格满足两个条件:
(1)缺失数据属于 MCAR;
(2)数据缺失之后的各时间点观测值均为能够访视到的最后一次时间点的观测值。若不满足第二条件,该方法的缺陷也显而易见,填充的数据会违背真实趋势(如图),而这一条件在实际工作中较难实现,往往需要病例脱落时已处于平台期。
例:(1)满足条件 2:黄斑变性患者经抗 VEGF 治疗后视力提升至 0.4 后不再变化,随后失访,使用末次随访视力 0.4 作为后续全部访视数据,对结果无影响。
(2)不满足条件 2:葡萄膜炎患者经激素冲击治疗后,视力由 0.1 逐渐提高,但随后失访,使用末次随访视力 0.4 作为后续全部访视数据,而患者真实视力还在进一步变化(提高至 1.0 或跌至 0.1),严重误判了治疗效果。
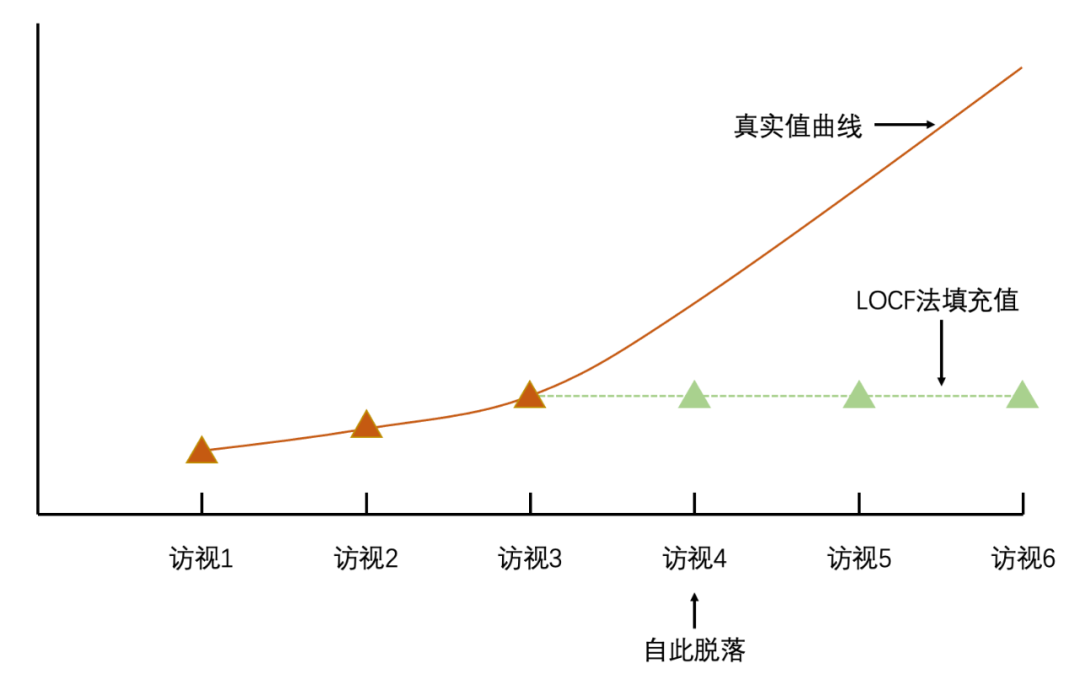
图源:笔者自制
3. 基线观测值结转(baseline observation carried forward,BOCF):
用疗效指标的基线值来对缺失数据进行填补。
这种方法适用于对于因不良反应而脱落的受试者, 以体现这些受试者的风险获益情况,填补后所得结论较为保守。
例:使用地塞米松玻璃体内植入剂治疗视网膜静脉阻塞继发的黄斑水肿,视力有所好转,但很快由于眼压升高而脱落,患者还未真正从试验治疗中获益就因不良反应脱落,为了估计风险获益情况,使用基线视力来填补后续缺失数据。
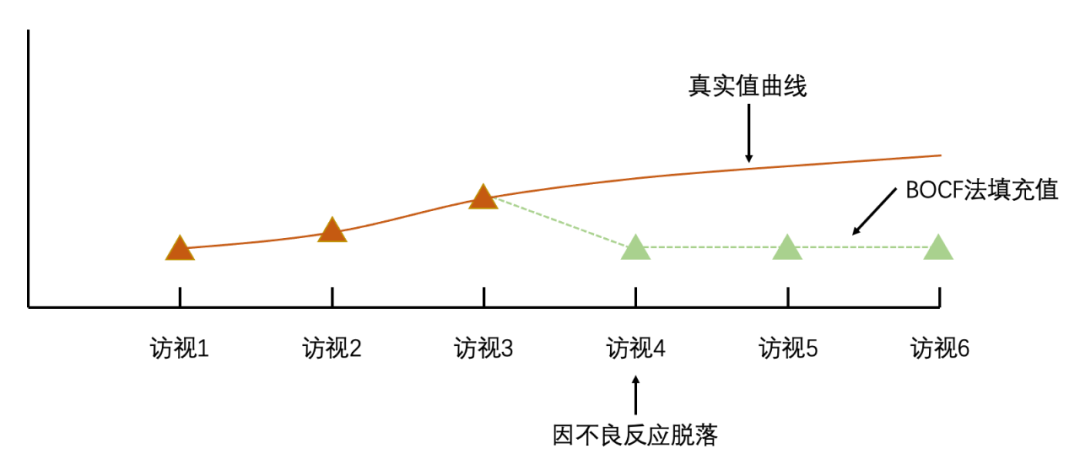
图源:笔者自制
4. 最差一次观测值结转(worsts observation carried forward,WOCF):
用已观察到的历次访视中最差的一次观测值对缺失数据进行填补。
这种方法常用于因缺乏疗效而脱落的受试者(一般要求受试者达到了一定疗程后脱落), 在评估时应结合其他客观指标, 以避免药物疗效未显现就发生脱落。这种方法填补后所得结论较为保守。
例:对白内障术后黄斑水肿患者行非甾体类抗炎药治疗,但水肿并未完全消退,且视力波动,一个治疗周期后患者失访,此时以治疗过程中最差一次数据(视力最差或水肿最严重)填补后续缺失数据,从而最保守地估计疗效。
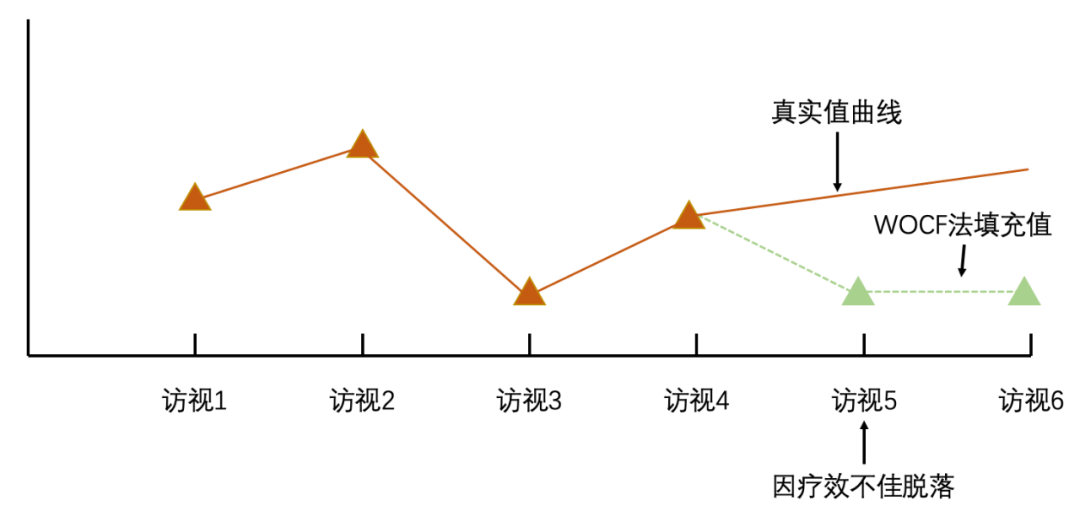
图源:笔者自制
5. 多重填补法(multiple imputation,MI):
是指对缺失数据进行多次填补后, 对多个填补后数据集进行统计分析和结果合并,适用于满足 MCAR 和 MAR 的缺失数据。
这种方法一般包括数据填补和合并分析两个步骤:
数据填补首先根据已观察到的数据来估计缺失数据的分布状态,利用合适的填补模型(模型根据数据缺失的机制来决定)进行 N 次填补。
在合并分析中, 首先对 N 个填补后数据集进行统计分析, 再对 N 次分析的结果进行合并。显然 MI 更为繁琐,工作量也更大,但结果也相对稳健。
四、小结
1. 各种补救措施可以对缺失数据进行替代、补充,从而尽量还原真实情况,但仍会带来偏倚,严格进行数据核查和避免数据缺失是临床试验的关键环节。
2. 非随机缺失尚无很好的处理方法。
3. 不同的处理方法也有不同的适用场景,如直接剔除和 LOCF 适用于满足 MCAR 的缺失数据;BOCF 和 WOCF 则在评估药物疗效与安全性时更加保守。
4. 另外也有均值插补法、重复测量数据混合效应模型法等其他方法可供选用。
5. 数据量较小的缺失数据填补可人工完成,为提高工作效率可借助 Excel、SPSS(替换缺失值和缺失值分析等)、SAS(PROC MI 和 PROC MIANALYZE 等)、R(MICE 包等)或 Python 等协助处理。
丁香科研精品技能课 1 分钱学
内含外泌体、SCI 写作、文献检索
综述指导教学等海量科研课
👇👇👇