【GEO 应用】GEO2R 分析工具更新大解析!不会 R 也能做生信
科研论文时间
GEO2R 是一个针对 GEO 数据库中表达谱芯片进行进一步差异分析的工具,利用这个工具我们可以比较 GEO 系列数据中的两组或更多组样品,获得差异性表达基因。
而差异基因在医学数据挖掘领域可以说是扮演者举足轻重的位置,无论是肿瘤还是非肿瘤领域的科研很多都是围绕差异基因展开分析。
最近,GEOR2 分析工具再次更新啦,随着这次更新,它给我们带来了很多新的功能,比如同时可以获得火山图、平均差图、 UMAP 图、韦恩图、表达密度图、P 值直方图、样本分位数图、平均方差趋势图。
与更新前相比,这些图可以帮助我们评估样本分组的标准化。也就是说,它们可以帮助我们确定我们设置的分组及其数据是否适合进行进一步分析,以及帮助我们判断是否需要对测试分组进行调整。
当然,最重要的是这些图竟然可以在文章中直接使用,零代码出这么多漂亮又实用的图。
这些新增加的功能不仅可以让我们更好的分析挖掘 GEO 数据,而且可以让不会 R 语言编程的研究者也可以进行数据统计分析,为进一步寻找分析差异基因和撰写生物信息文章带来了许多便利。
下面,笔者将对 GEO2R 的使用和新功能进行一下简要的介绍。
一、序列号检索
首先,进入 GEO 数据库官网:
https://www.ncbi.nlm.nih.gov/geo/
在 GEO 数据库检索框内输入你想要进行分析的芯片序列号,当然这里也可以直接按照关键词的方式来检索。
我们以「GSE79973」为例,点击「Search」。如果这个芯片与多个平台相关联,那么就选择感兴趣的平台。

图片来源:网站截图
二、GEO2R 分析
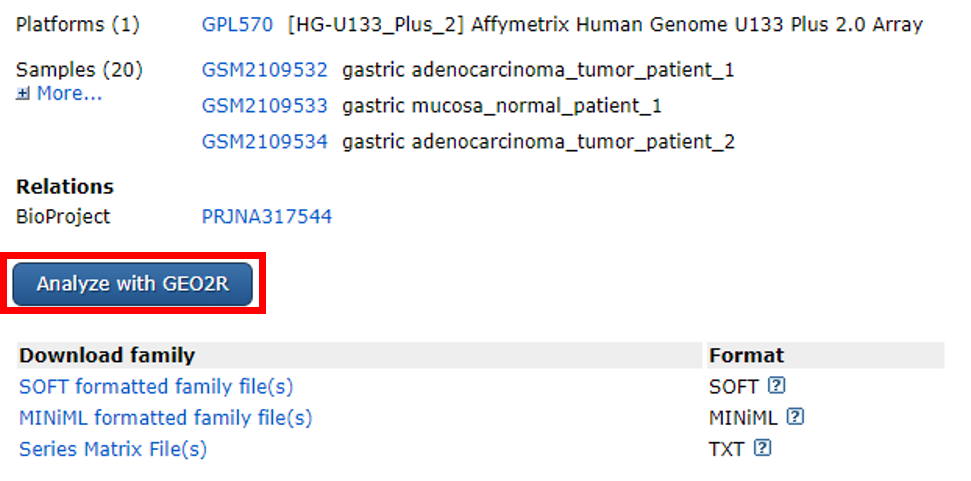
在结果页面下拉,点击「Analyze with GEO2R」进行分析。这里大家要注意,GEO2R 主要是对芯片数据(array)进行分析,但不是所有系列数据都能用 GEO2R 工具进行分析。
比如,测序数据就不可以进行 GEO2R 分析,因此,在检索结果页面不会显示「Analyze with GEO2R」按钮。
图片来源:网站截图
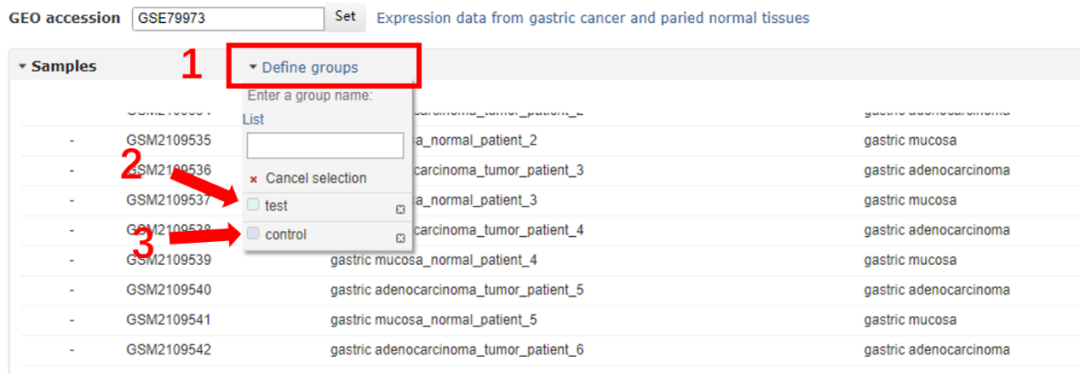
三、设置分组
在「Samples」表格中,单击「Define groups」进行分组,输入要比较的样品组的名称,例如,「test」和「control」。
最多可以定义 10 个组。为了保证分析能够正常进行,必须至少定义两个组别。点击组名右侧的叉图标可以删除该组。对于 2 组比较,通常首先定义对照组,然后定义测试组。
图片来源:网站截图
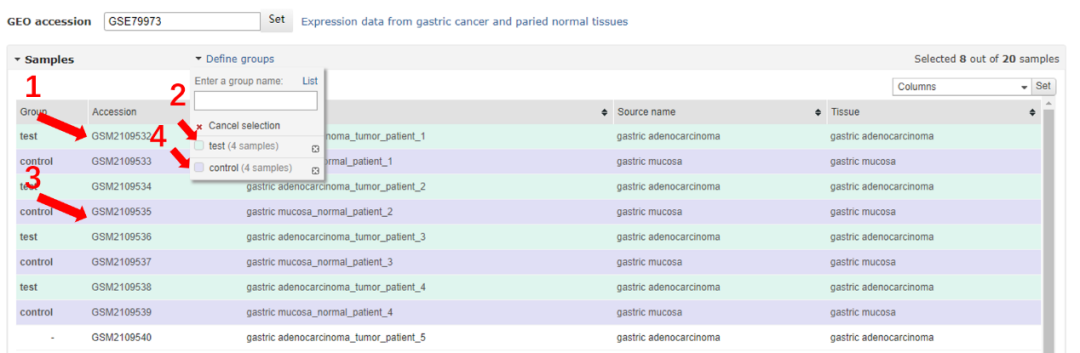
四、样品分配
用鼠标单击样品栏突出显示相关的样本行,或使用「Ctrl」或「Shift」键,可以突出显示多行。之后,单击组名称以将那些样本分配给该组。其他组同样重复上述步骤。
注意:并不需要选择系列中的所有样品才能进行分析。本次我们以每组选择 4 个为例。
图片来源:网站截图
五、执行分析
将样品分配到组后,单击表格下方「Analyze」按钮以默认参数运行分析。或者,我们可以在「Options」中编辑默认分析参数。
例如,我们可以设置其他 P 值等。我们可以在不分配组别的情况下单击「分析」按钮,并检索得 UMAP,箱线图,表达式密度和平均方差趋势图。
这些图可以帮助您评估标准化状态和样本分组,也就是说,它们可以帮助我们确定研究是否适合进行进一步分析,以及是否对测试进行任何调整。
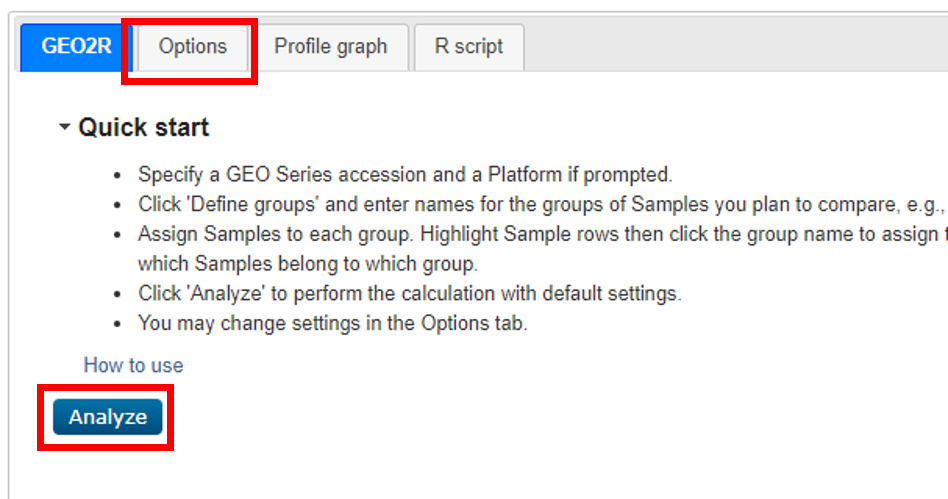
图片来源:网站截图
分析结果图形图表相结合,不仅以帮助可视化差异表达的基因还可以快速评估数据集质量。
1. 显著差异基因列表
结果显示为按 P 值排名的前 250 个基因的表格。P 值越小基因差异性越显著。单击其中某一行,可以显示该基因的基因表达谱图。
图形中的每个红色条形表示原始数据中该基因的表达量。图表底部还列出了样品的编号和组名。
如果想要查看包括排名前 250 个基因的所有差异基因以及基因的更多信息,可以点击「Download full table」链接下载完整数据表格,下载的表格可以在 Excel 中打开。
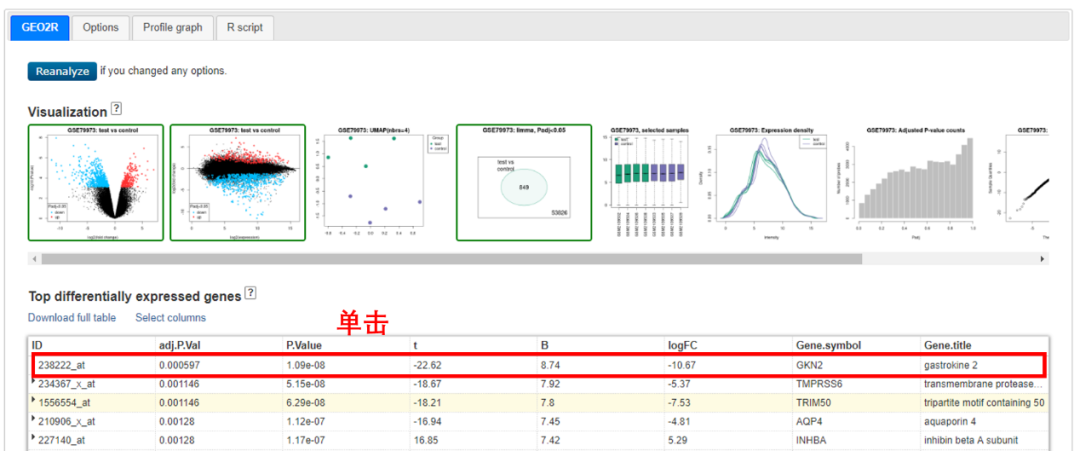
图片来源:网站截图

图片来源:网站截图
2. 火山图
图中每一个点代表一个基因,由 limma(volcanoplot)算法生成,火山图可以显示统计显著性(-log10 P 值)与变化幅度(log2 倍变化)的对比,可用于可视化差异表达的基因。
单击「Explore and download」链接可以下载高清原始图片。有颜色的点代表差异表达显著的基因,(红色 = 上调,蓝色 = 下调)。
我们可以在「Options」选项中设置火山图显示单个对比的测试结果(对比是一个样品组与另一个样品组的对比)。
因此,如果我们在分析中定义了两个以上的样品组,则会为每个对比组生成一个单独的图。
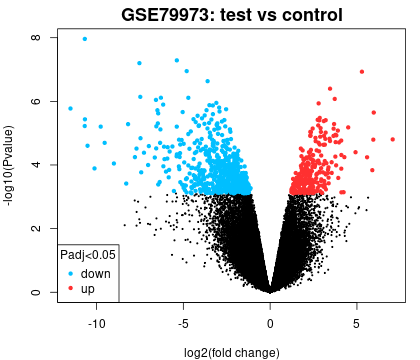
图片来源:网站截图
3. 平均差图
使用 limma(plotMD)包生成的平均差(MD)图可以显示 log2 倍数变化与平均 log2 表达值之间的关系,用于可视化差异表达的基因。类似于火山图,有颜色标记的基因表示显著差异表达(红色 = 上调,蓝色 = 下调)。
我们同样可以在「Options」中更改 P 值的设定。使用下载重要基因按钮可下载每种对比中突出显示的基因。
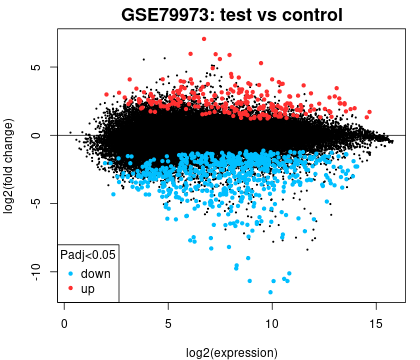
图片来源:网站截图
4. UMAP 图
使用 umap 生成的降维图可用于可视化样本之间的相互关系。
也可以在不选择「Samples」组的情况下生成此图,只需在定义组之前单击「Analyze」即可。这张图可以帮助判断,定义的两组样本是否整体上确实存在比较明显的差别。
比如,下图所示 test 和 control 的各自 4 例样本整体还是比较能分开,说明这两组之间在表达谱层面还是有比较明显的整体差异特征。
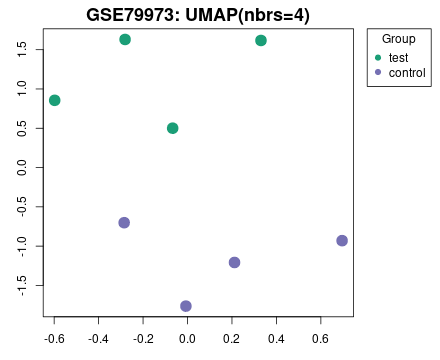
图片来源:网站截图
5. 维恩图
使用 limma(vennDiagram)算法生成,用于研究多个组别之间重要基因的重叠关系。可以下载维恩图上每个区域的基因。
但是这部分的分析具有一定的局限性:
最多可以绘制 5 个对比数据。当定义了 > 5 个组时,默认显示最高和最低表达基因数的对比。
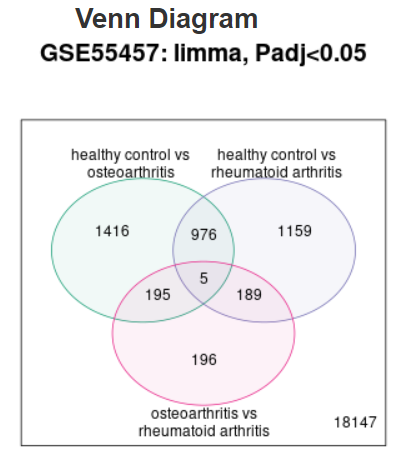
图片来源:网站截图
6. 箱形图
使用 R boxplot 算法生成,用于查看所选样本的值分布。样品根据分组显示不同的颜色。
查看分布对确定我们选择的样本是否适合差异表达分析很有帮助。通常来说,以中位数为中心的值表示数据已标准化且可交叉比较。
如果显示未能标准化,可以考虑在「Options」中选中「Force normalization」选项进行强制规范化,从而使所有选定的 Samples 具有相同的值分布。
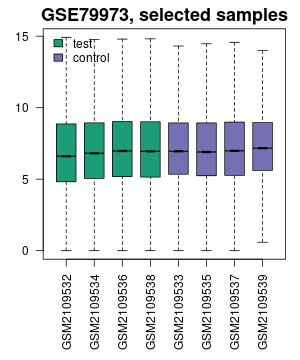
图片来源:网站截图
7. 表达密度图
使用 R limma(plotDensities)算法生成,表达密度图可用于查看所选 Samples 值的分布。是对箱型图数据的补充,用于在差异表达分析之前检查数据归一化,样品根据不同组别会显示不同颜色。
如果每个样品的密度曲线差异很大,则可以考虑在「Options」选项卡中选中「Force normalization」强制规范化。该图显示的是对数转换和归一化后的数据。
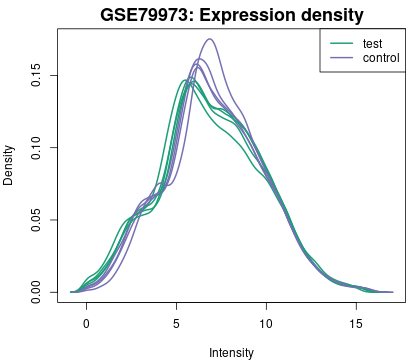
图片来源:网站截图
8. P 值直方图
使用 hist 算法生成,P 值直方图用于查看分析结果中 P 值的分布。此处的 P 值与之前最显著差异基因列表中的 P 值相同,并使用所有选定的对比度进行计算。
虽然显示的表格受大小限制(不能显示全部 250 个),但我们可以通过设置显示所有分析基因的 P 值分布来查看整图。
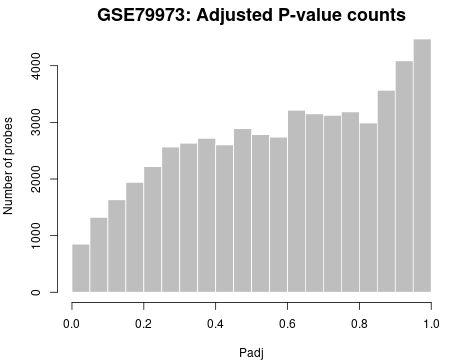
图片来源:网站截图
9. 样本分位数图
使用 limma(qqt)算法生成,根据 t 分布的理论分位数绘制数据样本的分位数。该图有助于评估 limma 测试结果的质量。
理想情况下,这些点应沿一条直线上,这会表明在测试过程中计算出的调节 t 统计量的值遵循其理论预测的分布。
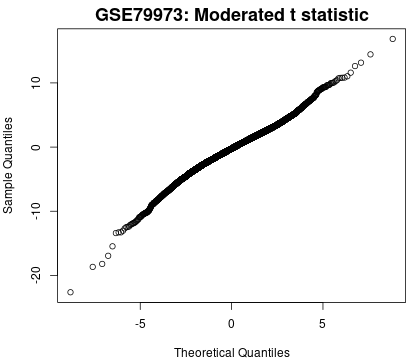
图片来源:网站截图
10. 平均方差趋势图
使用 R limma(plotSA, vooma)算法生成,拟合线性模型后,平均方差趋势图可以检查表达数据的均值-方差关系。
它可以帮助显示数据间是否变化过大。
当存在很强的均方差趋势时,精确权重可提高测试结果的准确性。该图不需要选择分组。每个点代表一个基因。红线是均值-方差趋势线,蓝线是固定方差近似值。
可以在不选择「Samples」组的情况下生成此图,只需在定义分组之前单击「Analyze」即可。
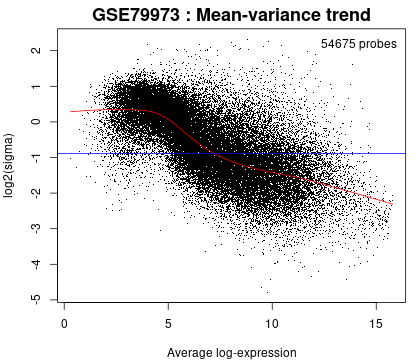
图片来源:网站截图
工具使用注意事项:
1. 制定数据分组时如果设置为两组的话,一定要先选择对照组,再选择处理组,否则后边得到的分析数据结果会是相反的。
2. 某些研究(例如双通道环路设计数据)可能会产生没有共同参考且无法直接比较的值。还有一些研究可能包含未规范化的样本值数据,可能就无法使用 GEO2R 工具。
3. 某些类别的 GEO 样本没有数据表(例如,高通量测序或基因组切片阵列),因此无法使用 GEO2R 进行分析。
整体而言,GEO2R 工具是可以分析大部分的 GEO 数据的,可以在不编程的情况下进行 GEO 数据差异分析,并且将数据结果变为图形可视化。帮助我们评估样本分组的标准化,以确定我们设置的分组及其数据是否适合进行进一步分析。
对我们深入挖掘 GEO 数据库中的数据带来了便利,同时也为不会编程的研究者带来了福音。

![methyl (1R,3R,4R,5S)-3-[(2R,3R,4R,5R,6R)-3-(allyloxycarbonylamino)-4,5-dihydroxy-6-(hydroxymethyl)tetrahydropyran-2-yl]oxy-5-ethyl-4-[(2S,3S,4R,5R,6S)-3,4,5-tribenzyloxy-6-methyl-tetrahydropyran-2-yl]oxy-cyclohexanecarboxylate,2609644-29-1,≥97%,阿拉丁](https://img1.dxycdn.com/p/s14/2024/0619/989/6399538481105633081.jpg!wh200)