丑闻!大佬署名论文,被曝抄袭,第一单位致歉:追责到人
生物学霸
近日,有网友在某乎提问:「如何看待智源、清华等单位论文 A Roadmap for Big Model 中大量段落被指涉嫌抄袭」。

图片来源:知乎
根据该网友描述,Google Brain 研究员 Nicholas Carlini 近日在一篇博客中指出智源、清华等单位的论文 A Roadmap for Big Model 中部分段落抄袭了他们的论文。同时 Nicholas Carlini还指出,该篇论文可能同时抄袭了十余篇其他论文。
这篇篇幅巨大的论文,作者署名甚至多达百人,足足用了第一页的篇幅罗列参与的作者。其中不乏清北等知名高校和学界的头部大佬,供职机构更是把中国知名高校和互联网巨头几乎一网打尽。在如此瞩目的阵容下却出现恶劣的论文抄袭事件,如此反差下一时将话题推上热搜,引发大量关注。
百人署名论文,竟被爆出多处抄袭
在曝光者 Nicholas Carlini 的博客中,菌菌发现问题论文是北京智源人工智能研究院 3 月份发布在预印本平台 arXiv 上的题为「A Roadmap for Big Model」综述论文。
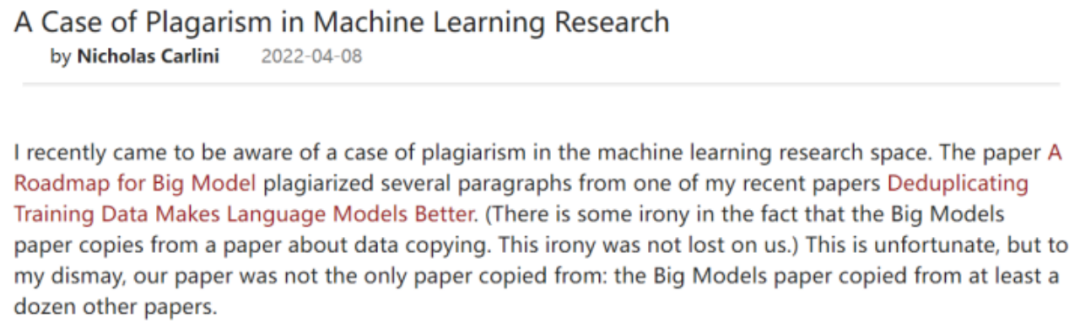
图片来源:博客截图
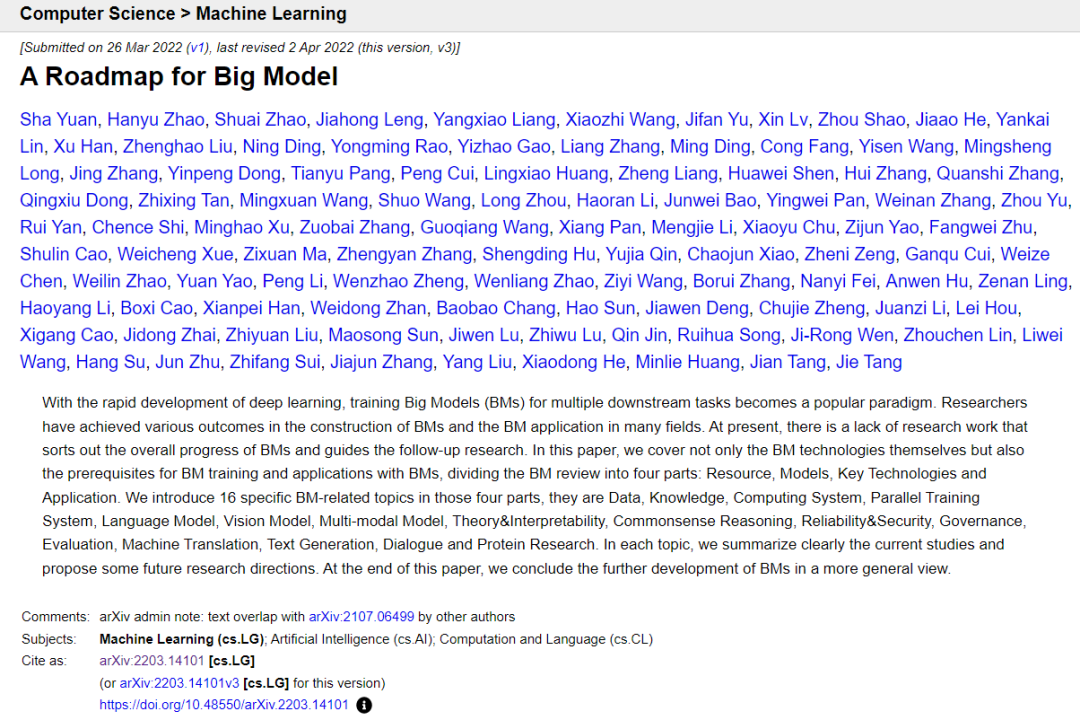
图片来源:论文截图
「A Roadmap for Big Model」是一篇长达 200 页、包含 16 篇文章的大模型领域的综述报告,智源研究院牵头负责框架设计和稿件汇总,邀请了清华大学、东北大学、纽约大学、北京大学、哥伦比亚大学、哈尔滨工业大学、北京航空航天大学、上海交通大学、蒙特利尔大学等国内外 100 位科研人员分别撰写了其 16 篇文章,每篇文章分别邀请了一组作者撰写并单独署名。被称为是神经网络大模型技术的发展蓝图。
具体而言,这篇大型综述介绍了16个相关的大模型,分别是:数据、知识、计算系统、平行训练系统、语言模型、视觉模型、多模块模型、理论&可解释性、常识推理、可靠性&安全、治理、评估、机器翻译、文本生成,以及对话和蛋白质研究。
按理来说,这样的大型综述报告应该是业内的经典和标杆论文,但根据Nicholas Carlini 的描述,上述论文不仅抄袭了自己团队的另外一篇题为「Deduplicating Training Data Makes Language Models Better」的论文,还指出该论文涉嫌抄袭十余篇其他作者的论文,这样的抄袭部分一共有10处。除此之外,Carlini 称他们的软件工具还检测出不少该文作者们自我抄袭的部分。

图片来源:论文截图

图片来源:Nicholas Carlini 博客截图|涉嫌抄袭的文本高亮显示,这样的抄袭部分一共有10处
值得一提的是,为了避免误伤,Carlini 还制定了一个十分严格的查重标准,基本可以确保不会把一些比较通用的表述标定为重复。即便如此,该论文还是检测出大量重复表述。Carlini 及其团队对这种现象感到遗憾,当前存在的抄袭行为其实并不应该在这样的论文中发生。
官方火速致歉,启动第三方专家审查并追责
确实,这样的行为不论在这样的大型综述中,还是在任何一篇学术论文中都不应该发生。抄袭事件在网上迅速发酵之后,智源研究院作为这一综述文章的组织者在其主页发布了致歉信,承认涉事论文有抄袭的部分,并向学界与公众表示歉意。

图片来源:网页截图
在致歉信中,智源研究院公布了内部调查的初步结果,为了避免大家太长不看,菌菌给大家大概总结一下:
-
涉事论文是是一篇大模型领域的综述,由智源研究院牵头,负责框架设计和稿件汇总,并邀请国内外100位科研人员分别撰写,报告发布后,根据反馈持续进行修改完善,到4月2日在arXiv网站上已经更新到第三版;
-
对于 Nicholas Carlini 反馈的抄袭情况,进行了核查,确认第2篇文章的第3.1节179个词,第8篇文章的第3.1节74个词、第12篇文章的第2.3节55个词、第14篇文章的第2节159个词、第16篇文章的第1节146个词与其他论文重复,应属抄袭;
-
智源即日将启动邀请第三方专家对报告进行独立审查,根据正式调查结果对相关责任人作出问责处理。
从智源发布的致歉信,我们不难看出,智源对于上述论文存在文字重复的情况已经定性为抄袭,并积极展开调查,体现了学术机构应有的担当。
4 月 13 日,Nicholas Carlini 也在其博客中更新:
任何学术不端都不应姑息
智源的初步调查结果总体来说令人信服,文章抄袭了就是抄袭了,没拿什么过度引用来应付公众。但比起对学术不端事件的定性,网友们更关心的可能还是后续对于相关责任人的调查和处理。
一个学术团体的学术诚信的建立需要很久,但想推倒,只需要这样一件恶劣的学术不端事件。学术机构对于这类事件的处理无疑对其公信力有着很大的影响。
虽然这样一篇大型综述涉及的作者多大百人,大佬比比皆是,但在学术不端面前,人人平等,既然选择了在这样一篇论文里挂名,首先要对得起挂名位置对应的学术贡献,其次也应当对这篇论文涉及的学术诚信等底线问题负责。
我们期待智源后续的调查结果,但事件有了结果,就告一段落了吗?
在如此大型的翻车事件背后,带来的社会影响同样不可忽视—— 在如此量级的学者中仍然有人缺乏学术规范方面的训练,这更值得我们重视。
对于抄袭,学术界一早就有十分明确的标准,抄了多少,怎么抄的,都有明确的划分。

图片来源:IEEE分级标准
「还有很多文章比这个抄袭的还严重」,「现在抄袭的文章太多了」并不能成为我们姑息论文抄袭的理由。千里的学术诚信之堤,就溃于这一个个学术不端的蚁穴。学术环境变得清朗或许道阻且长,但这同样不是我们摆烂甚至浑水摸鱼的借口。
除了抄袭这件板上钉钉的事,Nicholas Carlini 博客中提出另一个问题同样值得我们深思:
「一篇总括性综述文章(尤其是汇集了这么多业内优秀资源)的价值在于如何重新定义,构建该研究领域。直接复制粘贴之前其他综述内容并不能为该领域贡献任何新内容。」这才是写综述的意义不是吗?

![[精选]SCI论文写作投稿资料包:100+资料& 投稿答疑30问](https://img1.dxycdn.com/p/s14/2023/1105/569/6102685706544601271.jpg!wh200)