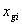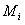三种基因表达差异的显著性分析方法
互联网
- 相关专题
- DNA微阵列基因表达数据分析
用于检测基因表达 水平的 DNA 微阵列实验,应用之一是比较实验,目的是比较两个条件下的基因表达差异,从中识别出与条件相关的特异性基因,例如,识别可用于肿瘤分型的特异基因等。为了提高实验的可靠性,对于同一样本,往往有两次或更多次的重复实验,但是,由于 DNA 微阵列的费用仍然很昂贵,不可能重复足够多的次数来满足实验数据分析的要求,因此需要采用统计方法来分析这些数据。对于这些表达数据的分析,目的就是要识别在两个条件下有显著表达差异的基因。何谓显著表达差异?通常是指一个基因在两个条件中表达水平的检测值在排除实验、检测等因素外,达到一定的差异,具有统计学意义,同时也具有生物学意义。常用的分析方法有三类,第一类称之为倍数分析,计算每一个基因在两个条件下的 Ratio 值,若大于给定阈值,则为表达差异显著的基因;第二类方法采用统计分析中的 t 检验和方差分析,计算表达差异的置信度,来分析差异是否具有统计显著性;第三类是建模的方法,通过确定两个条件下的模型参数是否相同来判断表达差异的显著性,例如贝叶斯方法。
倍数分析
早期基于 cDNA 微阵列技术的比较实验,用倍数来分析基因表达 水平差异,即计算基因在两个条件下表达水平的 Ratio 值。用t 检验
于两个条件下的多次重复实验,为了判断基因的表达差异是否具有显著性,在应用中较多的是采用假设检验,包括两个条件下的 t 检验和多个条件下的方差分析( ANOVA ),这里仅仅介绍 t 检验,关于 ANOVA 请参考相应的统计分析书籍。
零假设为<center> <img alt="三种基因表达差异的显著性分析方法" height="57" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591365.png" width="162" /></center> <center> &<u>NBS</u> p;</center> (8-6) 其中
 ,
,在 t 假设检验中,经常使用的显著性水平是 p =0.01 ,其意思是在零假设正确的情况下,从总体中进行 100 次抽样,允许有 1 次不满足零假设。对于 DNA 微阵列实验,检测的基因数目巨大,如果微阵列上有 10000 个基因,采用 p =0.01 ,将会有 100 个基因是由于偶然性而被错误认为是有表达差异显著的。这个数目已经可能对后续的生物学分析产生很大的干扰,从而导致 t 检验分析结果的不可靠或失去意义。
为了解决这个问题,可以对 t 检验进行改进,降低由于分母上方差小而带来的错误,因此对 t 检验的计算公式修改如下:
<center> <img alt="三种基因表达差异的显著性分析方法" height="50" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591364.png" width="102" /> (8-7)</center> <center> </center> <center> <img alt="三种基因表达差异的显著性分析方法" height="34" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591359.png" width="296" /> (8-8)</center> <center> </center> <center> <img alt="三种基因表达差异的显著性分析方法" height="24" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591338.png" width="193" /> (8-9)</center>8.3.3 贝叶斯分析
由于 DNA 微阵列数据噪声大、波动大,而且在大量数据的背后还有很多相关变量不能被观察到,因此,贝叶斯方法可以用来分析微阵列表达数据。贝叶斯分析可以简单描述如下:
<center> <img alt="三种基因表达差异的显著性分析方法" height="22" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591347.png" width="226" /></center> <center> </center> (8-10) 其中, P(M|D) 表示由观测数据集 D 得到参数化模型 <center> </center> <center> <img alt="三种基因表达差异的显著性分析方法" height="22" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591351.png" width="77" /></center>为真的概率,称为后验概率; P(M) 称为先验概率,表示在没有得到任何数据之前所估计的模型 M 为真的概率; P(D|M) 是指似然度,表示从模型 M 得到一个观测数据集 D 的概率。贝叶斯推断是通过参数估计和模型选择来实现任务的,最常用的方法是最大后验概率 (MAP) 估计和最大似然 (ML) 估计。在用贝叶斯方法分析表达数据时,首先假设在给定条件下,一个基因的表达水平测量值是独立的,并满足正态分布。根据经验,这一假设是合理的,特别是表达水平的对数大致服从对数正态分布。对于重复实验,也可以引入伽玛分布、高斯 / 伽玛混合分布等。一个基因在一种条件下的表达测量值可以用一个正态分布
<center> <img alt="三种基因表达差异的显著性分析方法" height="25" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591363.png" width="81" /></center> <center> </center> 来建模。对于每个基因在每一种条件下,都对应有一个双参数模型 <center> </center> <center> <img alt="三种基因表达差异的显著性分析方法" height="25" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591356.png" width="81" /> ,似然函数可以由下式给出:</center> <center> </center> <center> <img alt="三种基因表达差异的显著性分析方法" height="63" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591366.png" width="586" /> (8-11)</center> <center> </center> i 取遍所有的重复测量,重复测量次数为 n ,C表示归一化常数。似然度取决于充分统计量 n 、其中
<center> <img alt="三种基因表达差异的显著性分析方法" height="142" src="http://img.dxycdn.com/trademd/upload/asset/meeting/2013/08/27/A1377591353.png" width="282" /> (8-14)</center> <center> </center>




![β-衣托肟[用于金属分析],607-28-3,阿拉丁](https://img1.dxycdn.com/p/s14/2024/0619/381/2760431817860733081.jpg!wh200)