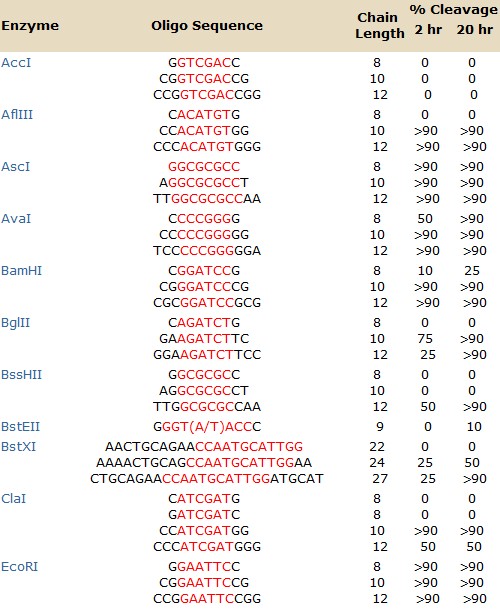
| 酶 | 寡核苷酸序列 | 切割率
% |
| 2 hr | 20 hr |
| Acc I
| G
GTCGAC
C
CG
GTCGAC
CG
CCG
GTCGAC
CGG | 0
0
0 | 0
0
0 |
| Afl III | C
ACATGT
G
CC
ACATGT
GG
CCC
ACATGT
GGG | 0
>90
>90 | 0
>90
>90 |
| Asc I | GGCGCGCC
A
GGCGCGCC
T
TT
GGCGCGCC
AA | >90
>90
>90 | >90
>90
>90 |
| Ava I | C
CCCGGG
G
CC
CCCGGG
GG
TCC
CCCGGG
GGA | 50
>90
>90 | >90
>90
>90 |
| BamH I
| C
GGATCC
G
CG
GGATCC
CG
CGC
GGATCC
GCG | 10
>90
>90 | 25
>90
>90 |
| Bgl II | C
AGATCT
G
GA
AGATCT
TC
GGA
AGATCT
TCC | 0
75
25 | 0
>90
>90 |
| BssH II | G
GCGCGC
C
AG
GCGCGC
CT
TTG
GCGCGC
CAA | 0
0
50 | 0
0
>90 |
| BstE II | G
GGT(A/T)ACC
C | 0 | 10 |
| BstX I | AACTGCAGAA
CCAATGCATTGG
AAAACTGCAG
CCAATGCATTGG
AA
CTGCAGAA
CCAATGCATTGG
ATGCAT | 0
25
25 | 0
50
>90 |
| Cla I
| C
ATCGAT
G
G
ATCGAT
C
CC
ATCGAT
GG
CCC
ATCGAT
GGG | 0
0
>90
50 | 0
0
>90
50 |
| EcoR I
| G
GAATTC
C
CG
GAATTC
CG
CCG
GAATTC
CGG | >90
>90
>90 | >90
>90
>90 |
| Hae III
| GG
GGCC
CC
AGC
GGCC
GCT
TTGC
GGCC
GCAA | >90
>90
>90 | >90
>90
>90 |
| Hind III | C
AAGCTT
G
CC
AAGCTT
GG
CCC
AAGCTT
GGG | 0
0
10 | 0
0
75 |
| Kpn I
| G
GGTACC
C
GG
GGTACC
CC
CGG
GGTACC
CCG | 0
>90
>90 | 0
>90
>90 |
| Mlu I
| G
ACGCGT
C
CG
ACGCGT
CG | 0
25 | 0
50 |
| Nco I
| C
CCATGG
G
CATG
CCATGG
CATG | 0
50 | 0
75 |
| Nde I | C
CATATG
G
CC
CATATG
GG
CGC
CATATG
GCG
GGGTTT
CATATG
AAACCC
GGAATTC
CATATG
GAATTCC
GGGAATTC
CATATG
GAATTCCC | 0
0
0
0
75
75 | 0
0
0
0
>90
>90 |
| Nhe I | G
GCTAGC
C
CG
GCTAGC
CG
CTA
GCTAGC
TAG | 0
10
10 | 0
25
50 |
Not I | TT
GCGGCCGC
AA
ATTT
GCGGCCGC
TTTA
AAATAT
GCGGCCGC
TATAAA
ATAAGAAT
GCGGCCGC
TAAACTAT
AAGGAAAAAA
GCGGCCGC
AAAAGGAAAA | 0
10
10
25
25 | 0
10
10
90
>90 |
Nsi I | TGC
ATGCAT
GCA
CCA
ATGCAT
TGGTTCTGCAGTT | 10
>90 | >90
>90 |
Pac I | TTAATTAA
G
TTAATTAA
C
CC
TTAATTAA
GG | 0
0
0 | 0
25
>90 |
Pme I | GTTTAAAC
G
GTTTAAAC
C
GG
GTTTAAAC
CC
AGCTTT
GTTTAAAC
GGCGCGCCGG | 0
0
0
75 | 0
25
50
>90 |
Pst I | G
CTGCAG
C
TGCA
CTGCAG
TGCA
AA
CTGCAG
AACCAATGCATTGG
AAAA
CTGCAG
CCAATGCATTGGAA
CTGCAG
AACCAATGCATTGGATGCAT | 0
10
>90
>90
0 | 0
10
>90
>90
0 |
Pvu I | C
CGATCG
G
AT
CGATCG
AT
TCG
CGATCG
CGA | 0
10
0 | 0
25
10 |
Sac I | C
GAGCTC
G | 10 | 10 |
Sac II | G
CCGCGG
C
TCC
CCGCGG
GGA | 0
50 | 0
>90 |
Sal I | GTCGAC
GTCAAAAGGCCATAGCGGCCGC
GC
GTCGAC
GTCTTGGCCATAGCGGCCGCGG
ACGC
GTCGAC
GTCGGCCATAGCGGCCGCGGAA | 0
10
10 | 0
50
75 |
Sca I | G
AGTACT
C
AAA
AGTACT
TTT | 10
75 | 25
75 |
Sma I | CCCGGG
C
CCCGGG
G
CC
CCCGGG
GG
TCC
CCCGGG
GGA | 0
0
10
>90 | 10
10
50
>90 |
Spe I | G
ACTAGT
C
GG
ACTAGT
CC
CGG
ACTAGT
CCG
CTAG
ACTAGT
CTAG | 10
10
0
0 | >90
>90
50
50 |
Sph I | G
GCATGC
C
CAT
GCATGC
ATG
ACAT
GCATGC
ATGT | 0
0
10 | 0
25
50 |
Stu I | A
AGGCCT
T
GA
AGGCCT
TC
AAA
AGGCCT
TTT | >90
>90
>90 | >90
>90
>90 |
Xba I | C
TCTAGA
G
GC
TCTAGA
GC
TGC
TCTAGA
GCA
CTAG
TCTAGA
CTAG | 0
>90
75
75 | 0
>90
>90
>90 |
Xho I | C
CTCGAG
G
CC
CTCGAG
GG
CCG
CTCGAG
CGG | 0
10
10 | 0
25
75 |
Xma I | C
CCCGGG
G
CC
CCCGGG
GG
CCC
CCCGGG
GGG
TCCC
CCCGGG
GGGA | 0
25
50
>90 | 0
75
>90
>90 |
| | | | |







](https://img1.dxycdn.com/2023/0724/527/4095307006030633861-14.jpg!wh200)