基于基因表达谱的基因调控网络研究
互联网
基因表达存在组织特异性、细胞周期特异性和外界信号的响应特异性等特性,这些特异性都是由细胞内复杂而有序的调控机制实现的。对基因表达调控机制的研究具有非常重要的理论和应用价值,研究的目的是要回答以下问题:在特定的细胞转态下,有哪些基因发生了表达?
它们是通过何种方式被调控的?它们的表达量是多少?这些基因的产物对细胞的生理活动会产生什么影响?诸如这些问题的答案将揭示生命奥秘和指导临床实践,例如,可以通过测量基因的表达调控产物来诊断疾病、指导治疗;可以人为干扰细胞的调控路径来改变细胞的状态等。基因表达调控的研究是后基因组时代的核心内容,是系统生物学的主要研究内容。
基因表达的过程包括染色质结构改变和基因活化、转录、 mRNA 加工和转运、翻译和蛋白质修饰、 mRNA 降解等过程,这些过程的实现都是通过蛋白质与蛋白质、蛋白质与核酸的相互作用来实现的。因此,基因表达调控的研究可以归结为物质之间相互作用以及物质的代谢过程,可以形成物质之间相互连接的网络。
如果抽象为数学问题,则可以用有向图来表示,图的顶点表示物质(蛋白质或核酸),边表示为相互作用。对于每个顶点,有状态的切换或者是物质浓度的变化,这种变化反映了网络的动力学特性。对于稳定系统,每个顶点的状态最终可以达到相对平衡。作为网络的整体特性可能是单稳态,或者是具有多个吸引子的混沌态。
要了解细胞的基因表达调控过程,必须对细胞内的各类物质进行全面和系统的测量,根据各种物质的变化来构建复杂的调控网络。
但是,就目前的生物大分子测量技术而言,尚不能得到所有生物大分子和相关物质的这些数据。因此,要对生物学分子网络进行研究,在现阶段还存在数据缺乏的问题;同时,细胞内的基因、蛋白质等物质的数量非常大,要构建如此庞大的网络对于网络理论和计算性能也提出了挑战。
DNA 微阵列的广泛应用提供了海量的基因表达谱数据,即细胞内 mRNA 的相对或绝对数量,反映了基因转录的调控机制,而基因转录在基因表达环节中起着非常重要的作用。
基因在转录过程中,转录因子(蛋白质)与 DNA 的结合以激活基因的转录,而基因的表达产物有可能是转录因子,它又能激活或抑制其它基因的转录,如此继续下去,就形成一个基因调控路径 (gene regulatory pathway) 。
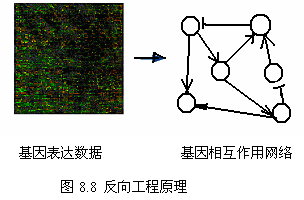
一条路径中的基因在表达水平上存在某种相关性,例如受同一个转录因子调控的基因往往是共表达的,这些生物学原理可以用于指导基因调控路径的构建。从表达谱数据出发,可以建立基因相互作用的网络模型,这种方法也称反向工程 (reverse engineering) 。最常用的基因调控网络模型是 Boolean 网络、连续模型、线性组合模型、加权矩阵模型、互信息关联模型等。
1 布尔网络模型
基因调控网络的一种最简单的模型就是布尔网络模型。在布尔网络中,每个基因所处的状态或者是“开”,或者是“关”。状态“开”表示一个基因转录表达,形成基因产物,而状态“关”则代表一个基因未转录。基因之间的相互作用关系由布尔表达式来表示,例如:
读作“如果 A 基因表达,并且 B 基因不表达,则 C 基因表达”。以有向图 G= ( V , F )表示布尔网络,其中 V 是图的节点集合,每个节点代表一个基因,或者代表一个环境刺激。环境刺激可以是任何相关的生物、物理或化学因素,但不是基因或基因的产物,它影响调控网络。而 F 是有向边的集合,每条边代表基因之间的相互作用关系。上例所对应的网络见 图 8.9 。
当一个节点代表基因时,该节点与一个稳定的表达水平相联系,表示对应基因产物的数量。如果一个节点代表环境因素,则节点的值对应于环境刺激量。各节点的值或者是“ 1 ”,或者是“ 0 ”,分别表示“高水平”和“低水平”。
网络中各个基因状态的集合成为整个系统的状态,当系统从一个状态转换到另一个状态时,每个基因根据其连接输入(相当于调控基因的状态)及其布尔规则确定其下一时刻的状态是否是“开”或“关”。布尔规则以“真值表”的形式表示。 表 8.2 列出当节点 A 、 B 处于不同状态时, C 的状态应当如何。
布尔网络从初始状态开始,经过一系列状态转换,最后到达系统的稳定状态。从不同的初始状态出发,布尔网络会到达不同的终止稳定状态,而这些不同的终止状态对应于细胞相对稳定的生化状态。如果在布尔网络的一个稳定状态下,所有基因的状态不变,则称该稳态是“点吸引子”;如果网络的一个稳态是多个状态的周期切换,则称该稳态为“动态吸引子”,此时网络系统处于相对稳定状态。具体来说,稳定状态分两种情况,一是单稳态,即系统状态不再改变。
,系统从状态( 1 ,0 ,0 )出发,经过一系列中间状态,到达单稳定状态以后,系统一直驻留在状态( 0 ,0 ,0 )。另一种稳定状态是所谓多稳态,即系统状态没有绝对稳定,只是相对稳定,系统在若干个状态之间循环往复。如 图 8.10(b) 所示,系统达到相对稳定,在状态( 0 ,0 ,1 )和状态( 1 ,1 ,0 )之间切换。
借助于机器学习或者其它智能训练的方法可以构建一个具体的布尔网络,即根据基因表达的实验数据建立待研究的基因之间的相互作用关系,确定每个基因的连接输入(或调控输入),并且为每个基因生成布尔表达式,或者形成网络系统的状态转换表。对于复杂的网络,在网络构造过程中,其搜索空间非常大,需要利用先验知识或合理的假设,以减小搜索空间,有效地构造布尔网络。
布尔网络模型简单,便于计算,但是由于它是一种离散的数学模型,不能很好地反映细胞中基因表达的实际情况,如,布尔网络不能反映各个基因表达的数值差异,不考虑各种基因作用大小的区别等。而在连续网络模型中,各个基因的表达数值是连续的,并且以具体的数值表示一个基因对其它基因的影响。
2 线性组合模型
线性组合模型是一种连续网络模型,在这种模型中,一个基因的表达值是若干个其它基因表达值的加权和。基本表示形式为:
其中, Xi ( t + D t ) 是基因 i 在 t + D t 时刻的表达水平, Xj ( t ) 是基因 j 在 t 时刻的表达水平,而 w ij 代表基因 j 的表达水平对基因 i 的影响。在这种基因相互关系表示形式中,还可以增加其它数据项,以逼近基因调控的实际情况。例如,可以增加一个常数项,反映一个基因在没有其它调控输入下的活化水平。
将上述表达式转换为线性差分方程,描述一个基因表达水平的变化趋势。这样,在给定一系列基因表达水平的实验数据之后,即给定每个基因的时间序列 Xi ( t ) ,就可以利用最小二乘法或者多重分析法求解整个系统的差分方程组,从而确定方程中的所有参数,即确定 w ij 。
最终,利用差分方程分析各个基因的表达行为。实验结果表明,该模型能够较好地拟合基因表达实验数据。
3 加权矩阵模型
加权矩阵模型与线性组合模型相似,在该模型中,一个基因的表达值是其它基因表达值的函数。含有 n 个基因的基因表达状态用 n 维空间中的向量 u (t)表示, u (t)的每一个元素代表一个基因在时刻 t 的表达水平。以一个加权矩阵 W 表示基因之间的相互调控作用, W 的每一行代表一个基因的所有调控输入, w ij 代表基因 j 的表达水平对基因 i 的影响。在时刻 t ,基因 j 对基因 i 的净调控输入为 j 的表达水平(即 u j (t) )乘以 j 对 i 的调控影响程度 W ij 。基因 i 的总调控输入 r i (t) 为:
这一形式与线性组合模型相似,若 W ij 为正值,则基因 j 激发基因 i 的表达,而负值表示基因 j 抑制基因 i 的表达, 0 表示基因 j 对基因 i 没有作用。与线性组合模型不同的是,基因 i 最终表达响应还需要经过一次非线性映射:
这种函数是神经网络中常用的 Sigmoid 函数,其中 a 和 b 是两个常数,规定非线性映射函数曲线的位置和曲度。通过上式,计算出 t+1 时刻基因 i 的表达水平。在最初阶段,加权矩阵的值是未知的。但是可以利用机器学习方法,根据基因表达数据估计加权矩阵中各个元素的值。
对于这样的模型,可以利用成熟的线性代数方法和神经网络方法进行分析。实验表明,该模型具有稳定的和周期稳定的基因表达水平,与实际生物系统相一致。在这种模型中还可以加入新的变量,模拟环境条件变化对基因表达水平的影响。
4 数据整合分析
从基因表达谱出发,构建基因调控网络,在不考虑由于实验过程产生的技术噪声等因素对建模的影响之外,最大的问题就是维度问题,以上所述的布尔网络等模型随着变量(基因数目)的增加,所需要的数据将呈指数级增长,计算复杂度也快速增长。对于推断 N 个基因的基因网络,我们需要多少个数据点?如果是完全没有条件约束的,对于全连接的布尔网络模型,需要测量所有 个输入 - 输出对。这对于实际上的基因数目,显然是不可想象的。
如果约束每个基因的输入数目不超过 K 个,规则表中所有的入口在 N 个独立的输入 - 输出对唯一确定后,数据点的数目大约是 的规模。要解决这个问题,一个有效的方法是降低网络的规模,即降低模型中节点之间的连结数目。很多研究表明,对于基因调控网络、蛋白 - 蛋白作用网络、代谢网络,没有必要构建全连接的网络结构,这些网络都属于无尺度网络( Scale-free network ),即具有 k 条边的节点分布几率 p(k) 满足泊松分布, 。
基因调控网络反映的是基因之间的相互关系,除了可以在基因表达数据中发现这种关系外,还可以在 DNA 序列、转录因子与顺式调控元件相互作用、蛋白 - 蛋白相互作用、蛋白在细胞中的定位等层面上反映出来。是否可以将这些生物学背景知识应用于基于表达谱的基因调控网络分析中呢?
答案是肯定的。充分利用现有的生物学知识,与表达数据相结合将成为基因调控网络研究的主流思路。
随着生物信息学和分子生物信息检测技术的发展,我们对基因关系的认识日益增多,利用这些知识可以构建初步的基因调控网络,进而用表达数据进行仿真和模拟;根据模拟结果修改模型,再结合生物学实验验证,可以完善基因调控网络。经过若干次的建模―模拟―实验循环可以逼近真实的生物学基因调控网络。
基因的表达是反式调控因子与顺式调控元件相互作用后启动的,调控因子和调控元件的结合具有序列特异性,利用这种特异性,结合基因表达数据,可以发现基因之间的相互调控关系,建立基因调控路径,构建基因调控网络。
全基因组定位分析( genome-wide location analysis )是一种新的研究蛋白质与 DNA 片段结合的分子生物学技术,利用微阵列技术,可以高通量研究转录因子与全基因组的基因间区序列结合的亲和力,从实验结果可以发现转录因子的调控基因,这些实验数据可以用来明确基因之间的相互关系。
蛋白质是基因调控的产物,蛋白质 - 蛋白质之间的结合能反映基因的相互作用关系。
酵母双杂交等实验可以高通量地获取蛋白之间相互作用的数据。蛋白质的结合可能是构成蛋白复合体,也可能是参与共同的生物学过程。虽然这些数据和知识不能反映它们的编码基因之间的直接调控关系,但是可以反映基因之间的相互关系,例如,共调控关系、或功能具有相关性等。
基因表达的时空特异性是一个重要特性,空间特异性表现在蛋白质定位在细胞中的不同位置。从蛋白质定位信息出发,可以得出编码位于相同位置的蛋白质编码基因之间的关系,这种关系也可以用于指导基因网络的构建。
以上所有信息都有助于构建基因调控路径和网络,在具体的应用中可以整合相关数据,但是,仍需要发展新的方法。基因调控路径和网络的研究对于生物信息学来说是一个重大挑战,它不仅需要有效的数据挖掘方法来整合和充分利用海量的异质和异源数据,还需要对基因调控的生物学知识有深层次的理解。
<center> <p> </p></center>