「干货」 如何利用 NCBI 寻找所需基因的信息?
丁香园论坛
今天在坛子里应助站友问题时,觉得有必要把自己在人类基因缺陷疾病基因诊断过程中积累的经验跟大家分享下。
以白仁战友应助的 CCR9 基因为例。
一、如何寻找基因信息
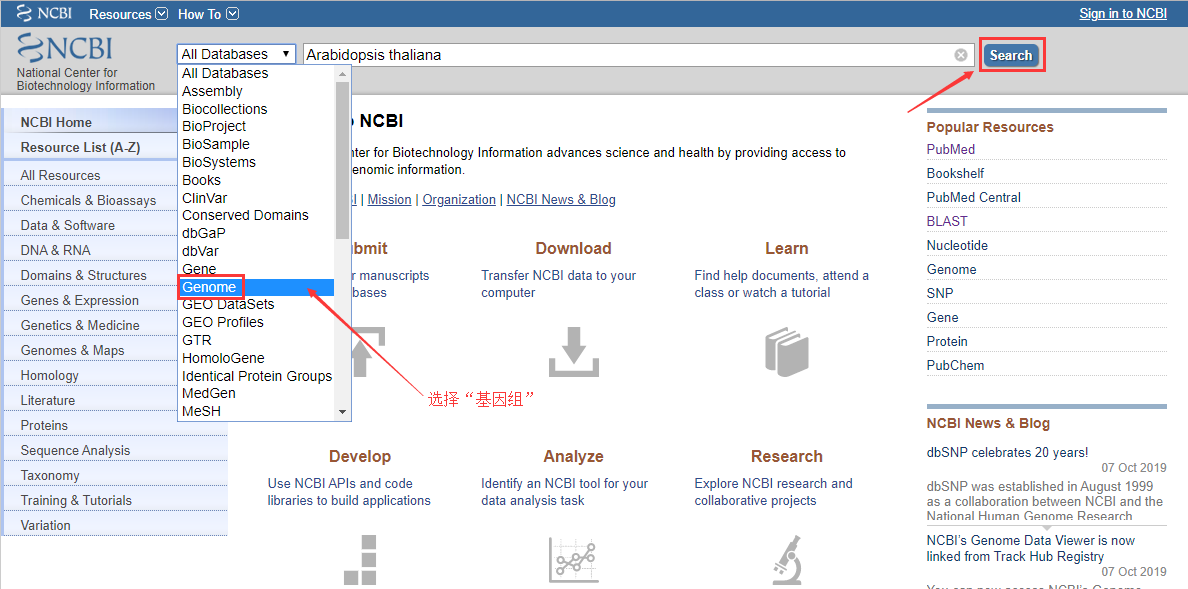
首先,打开 NCBI 网页 http://www.ncbi.nlm.nih.gov/pubmed/,选择「gene」,输入您要的基因名称(可简写),如 CCR9,搜索
然后,选择种属,如 homo sapiens,点击进入,http://www.ncbi.nlm.nih.gov/gene/10803;
然后,使劲往下拉网页,在"NCBI Reference sequence (Refseq)"下方,
NG_029472.1 就是该基因的 genomic DNA 序列号,
NM_001256369.1 就是异构体 B 的 mRNA 序列号,而 NP_001243298.1 就是 NM_001256369.1 相应的氨基酸序列号,
同理,NM_031200.2 → NP_112477.1 分别是异构体 A 的 mRNA 和氨基酸序列号。
点击进入相应页面就会出现详细的外显子、编码序列等信息。
二、如何选择目前公认的 mRNA 序列号?
在这儿推荐一个网站:mutation@glance,http://rapid.rcai.riken.jp/mutation/(您只能在 google 搜索中才能快速搜到,百度是搜不到的)。
输入您查找的基因,如 CCR9,"submit"提交,便会出现 CCR9 的相应界面,Reference sequence: NM_031200.2 这里所显示的就是公认的序列号。
这样您参照的序列号对了,您设计引物、基因突变的命名及表述才是对的,发文章时才不会错。(基因突变命名也是一个系统,可以到 NCBI 上下载相关文献)。
另外,这一网站也提供了目前文献报道的已知的突变位点和 SNP 位点。非常好用。
三、如何看懂 mRNA 的相关信息?
选好公认的 mRNA 序列号后,我们就可以利用其序列设计引物了。
以 CCR9 的公认序列号 NM_031200.2 为例。
1. source 中 map=map="3p21.3"是指此基因位于 3 号染色体短臂(p)2 带 1 区 3 亚区;
2. gene 1..2567 表示 CCR9 mRNA 长度 2567bp;
3. "CDS" 为 mRNA 编码氨基酸的序列:
translation="MTPTDFTSPIPNMADDYGSESTSSMEDYVNFNFTDFYCEKNNVRQFASHFLPPLYWLVFIVGALGNSLVILVYWYCTRVKTMTDMFLLNLAIADLLFLVTLPFWAIAAADQWKFQTFMCKVVNSMYKMNFYSCVLLIMCISVDRYIAIAQAMRAHTWREKRLLYSKMVCFTIWVLAAALCIPEILYSQIKEESGIAICTMVYPSDESTKLKSAVLTLKVILGFFLPFVVMACCYTIIIHTLIQAKKSSKHKALKVTITVLTVFVLSQFPYNCILLVQTIDAYAMFISNCAVSTNIDICFQVTQTIAFFHSCLNPVLYVFVGERFRRDLVKTLKNLGCISQAQWVSFTRREGSLKLSSMLLETTSGALSL" 引号所引就是 CCR9 基因编码的 CCR9 蛋白的氨基酸序列。
"60..1169",60 是编码 mRNA 的起始位置,所以 CCR9 基因(人)编码序列长度是 1169-60+1=1110bp,编码蛋白是由 1110/3=370 个氨基酸构成。
4. exon 是外显子相应的 mRNA 序列。如 exon 1..152 number=1,是指 exon1 对应的 mRNA 位置为 1 到 152,以此类推;
5. CDS 181..1290 可见 exon1(1..152)是不参与氨基酸的编码的,就是说转录了,但是经后期的翻译时被剪切修饰掉了;
6. ORIGIN 部分就是具体的碱基序列了,可以用来参照设计引物的。
这里我也还有没弄清楚的,如 STS、misc_feature 是什么意思?
注:我说的只是人的,病毒、动物的会有差异吧,不对之处请大家指出来我会虚心学习。
本文来自丁香园论坛
想了解更多有用的、有意思的前沿资讯以及酷炫的实验方法的你,都可以成为师兄的好伙伴
师兄微信号:shixiongcoming