简介
SPSS 数据整理功能主要通过菜单栏中的“数据”和“转换”项目来执行。
材料与仪器
步骤
SPSS 数据整理的基本过程可分为如下几步,下面将对数据排列、数据抽样、数据拆分、数据合并、计算变量等几个重要的数据整理操作进行举例介绍:
(一)数据排列
在整理和浏览整体数据时,对具体数据根据一定规律进行排列往往十分有用,SPSS 中的“排序个案”和“排列变量”可以方便地达到这个目的。“排序个案”功能与 Excel 中的排列功能类似,可以对一个或多个变量进行排序。
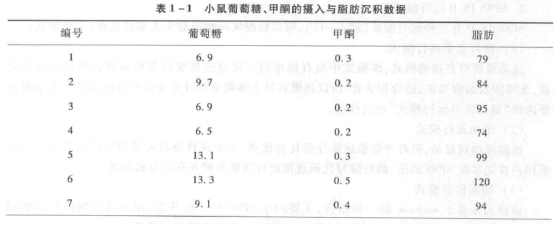
【例 1-5】将表 1-1 中的数据按照变量葡萄糖 (Glucose) 进行排序。
具体操作步骤如下:
① 输入数据 选择“文件”→“打开”→“数据”,选定 Excel 文件“小鼠脂肪.xls”导入,也可以通过复制和粘贴的方式输入数据。
② 数据整理 选择菜单中的“数据”→“排序个案”,在弹出对话框中选中“Glucose”项,将其添加到“排序依据”窗口中,点击“确定”。“排列变量”功能可对变量名称按需要的规律进行排列,方式与“排序个案”类似,此处不再赘述。
(二)数据抽样
在实际统计分析中,有时只需选取某些特定的对象进行操作而不需要对所有的观测值进行分析,SPSS 的“选择个案”命令可以实现这种样本筛选的功能。
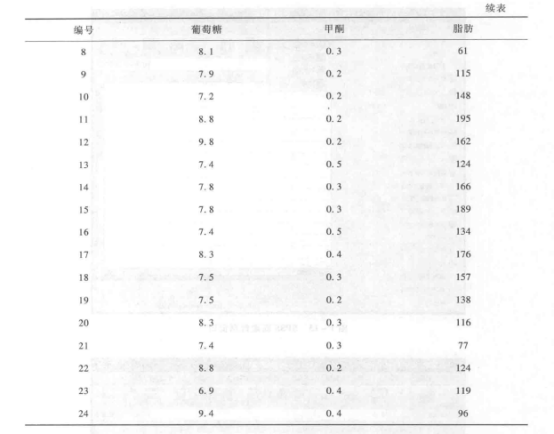
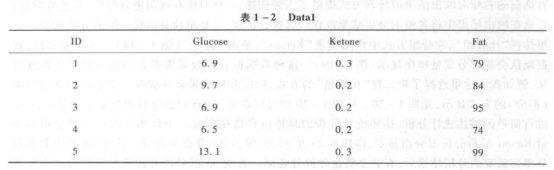
【例 1-6】将表 1-2 中脂肪沉积 (Fat) 大于 100 mg 的样本选择出来。
具体操作步骤为:
① 数据输入 同例 1-5。
② 数据抽样 选择菜单中的“数据”→“选择个案”,在弹出对话框中选择“如果条件满足”,点击“如果”按钮,打开“选择个案:If”对话框,见图 1-17。在“选择个案:If”对话框中,设置 Fat>100,点击“继续”即可。
(三)数据拆分
数据拆分功能可帮助操作者将文件中的观测值进行分组,再按照不同的分组进行后续分析。
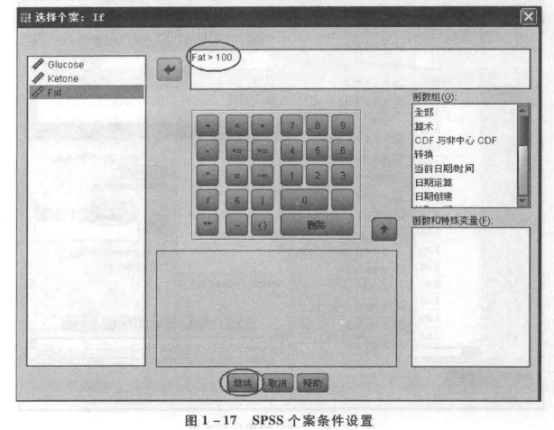
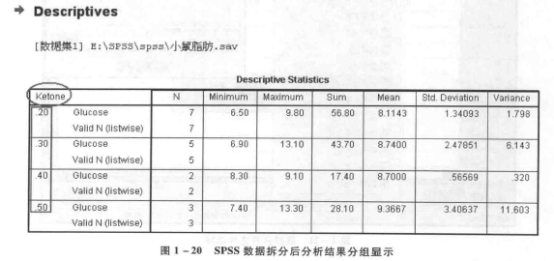
【例 1-7】将表 1-2 中数据按甲酮喂量 (Ketone) 进行样本数据拆分。
具体操作步骤为:
① 数据输入 同例 1-5。
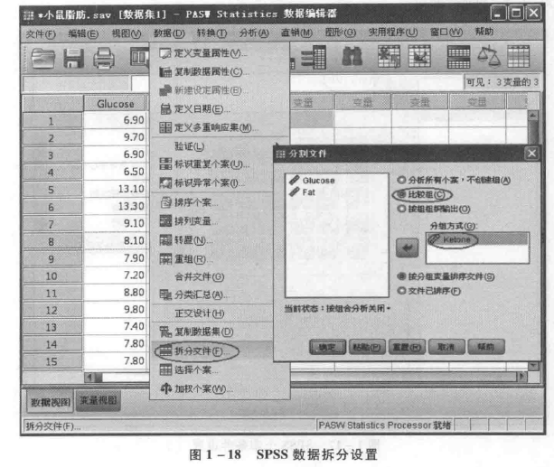
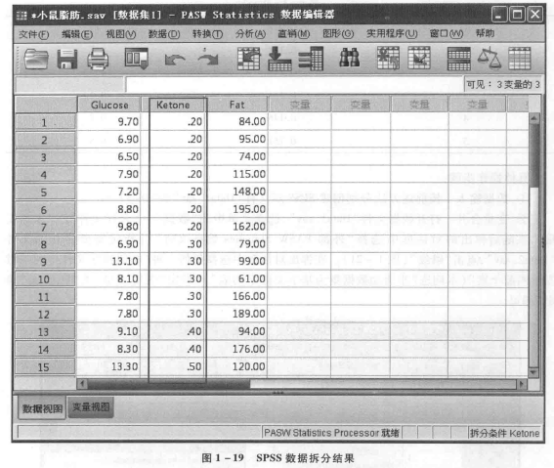
② 数据拆分 选择菜单中的“数据”→“拆分文件”,弹出“分割文件”对话框,见图 1-18。对话框的右侧对输出结果的排列方式提供了三种选择:一是对所有观测进行分析,不进行拆分;二是在输出结果中将各组的分析结果放在一起进行比较;三是单独显示每一组的分析结果。这里选择“比较组”,在分组方式中添加变量“Ketone”,单击“确定”(图 1-18)。拆分完成后,数据默认会按拆分变量排序显示(图 1-19)。这种数据拆分的效果需要在后续分析中才体现出来,例如我们这里选择了第二种“比较组”的方式,后续分析结果将存放在一个表格中并以分组(拆分)的方式显示,见图 1-20。从图 1-20 中可以看见,SPSS 对拆分后的数据中变量 Glucose 进行简单的描述统计分析(描述统计分析的具体内容将在实验二中具体介绍),结果会根据变量 Ketone 的拆分情况分组显示,即按 0.20、0.30、0.40、0.50 分成 4 部分。注意,在利用数据拆分得到需要的分析结果后,有必要将这种拆分还原。否则,在以后所有的后续统计分析中都将以拆分的数据进行并显示。还原拆分只需要选择图 1-18 中“比较组”上方的“分析所有个案,不创建组”即可。
(四)数据合并
数据合并功能在 SPSS 中非常实用,可分为添加个案的数据合并和添加变量的数据合并两种。前者可将新数据文件中的观测纵向合并到原始数据文件中,合并时两套数据需要有相同的变量和相同的变量顺序;后者则是将两个或多个数据文件进行横向合并,合并时两套数据需要有共同的标识变量(如表 1-2 中 ID),而且需要同样按升序排列且没有重复和缺失。下面我们用简单的数据实例来解释变量合并,其实数据合并功能更适合操作比较大的复杂文件。
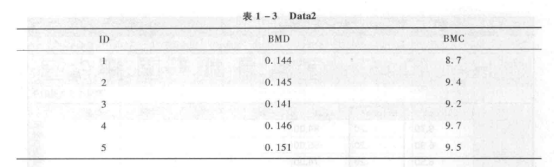
【例 1-8】将表 1-2 与表 1-3 合并成为一个 SPSS 数据文件。
具体操作步骤:
① 数据输入 按前述方法分别创建 SPSS 新文件“Datal.sav”和“Data2.sav”。
② 变量合并 打开数据文件“Datal.sav”,选择菜单中的“数据”→“合并文件”→“添加变量”,在随后弹出的对话框中选择“外部 PASW Statistics 数据文件”并指定需要合并的文件“Data2.sav”,点击“继续”(图 1-21)。在弹出对话框中选择任何一种“按照排序文件中的关键变量匹配个案”(本例选“非活动数据集为基于关键字的表”),指定“关键变量”为 ID,点击“确定”即可。
来源:丁香实验