材料与仪器
步骤
3.1 叶片和根组织的取材以及蛋白质沉淀
( 1 ) 从植物的中部切取未衰老的绿色叶片,立即放入自封塑料袋中冷冻。如果没有冷冻设备,可先放在冰上,然后再放到 -20°C 保存。
( 2 ) 挖出植物根系,在绿色茎段以下一英寸的地方取材。抖动根系,并快速的依次放入 3 个大烧杯中洗去土壤,然后再放入自封塑料袋中冷冻,或暂时保存在冰上。
( 3 ) 称取 2.5 g 去除了茎秆和其他物质的冰冻叶片和根系,用预冷的剪刀剪碎样品后 ,放入预冷的陶瓷研钵中,加液氮研磨至粉末,需要多次添加液氮,以保持组织的冰冻状态。
( 4 ) 把冰冻的叶片或根系粉末放入 40 ml 离心管中,加入 25 ml 叶片重悬液,振荡混合,确保所有的粉末被重悬起来后,在 -20°C 下静置 45 min,再振荡摇匀,35000 g 离心 15 min。
( 5 ) 用玻璃移液管吸去上清液,注意不要扰动沉淀。用等体积的 EDTA 洗液洗涤沉淀。振荡打散沉淀,冰上静置 5 min,35000 g 离心 15 min。重复操作至少两次,直到叶片蛋白质沉淀不再有绿色。
( 6 ) 冰冻干燥沉淀物,得到含有蛋白质、细胞壁和纤维的淡褐色材料。
3.2 从三氯乙酸/丙酮沉淀的粉末中制备蛋白质样品
( 1 ) 针对每个样品,分别称取 20 mg 的三氯乙酸/丙酮沉淀粉末(制备方法见 21.3.1 ) 放入有盖的 1.5 ml 离心管中。
( 2 ) 在每只管中加入 1 ml 的 100 mmol/L Tris-HCl ( pH 8.5 ) ,涡旋振荡 1 min,18000 g 离心 10 min,弃上清液(见注释 1)。
( 3 ) 在每只管中加入 500 μl 的 8 mol/L 尿素,涡旋振荡 5 min,超声波水浴处理 10 min,然后旋转振荡 30 min。
( 4 ) 18000 g 离心 10 min,将约 400 μl,含蛋白质浓度为 0.1~0.5 μg/μl ( 见注释 2 ) 的上清液移至另一只管中。
( 5 ) 用 8 mol/L 尿素重复第 3 和第 4 步骤,合并上清液,调整容积到 600 μl。
3.3 抽提蛋白质的蛋白酶消化
( 1 ) 在总容积为 600 μl 的蛋白抽提液中添加 5 μl 外切赖氨酸蛋白酶工作液,在旋转振荡器上 37°C 消化过夜(见注释 3) 。
( 2 ) 在每个样品中分别加入 2300 μl 的 100 mmol/L 碳酸氢铵,30 μl 的 100 mmol/L 氯化钙,60 μl 的乙腈,10 μl 的胰蛋白酶工作液。终浓度为:1.6 mol/L 尿素,76 mmol/L 碳酸氢铵,1 mmol/L 氯化钙,2% ( V/V ) 乙腈,3.3 ng/L 胰蛋白酶。
( 3 ) 在旋转振荡器上 37°C 消化 24~48 h。添加 60 μl 甲酸使终浓度为 2%,将样品保存在 -20℃ 备用。
( 4 ) 用 15 ml 含有 0.1% 甲酸的 90% 乙腈溶液平衡 C18 SeP- Pak 层析柱,然后用 20 ml 含有 0.1% 甲酸的双蒸水清洗柱子 4 次。
( 5 ) 吸取 3 ml 蛋白酶消化液加样到已平衡好的 C18 Sep-Pak 层析柱上,收集流出的液体,再重复慢速过柱两次。用 20 ml 含有 0.1% 甲酸的双蒸水洗柱子,洗脱盐及其他松散结合物质。再用 3 ml 含有 0.1% 的甲酸的 90% 乙腈溶液将肽段从 C18 Sep-Pak 柱上洗脱下来。
( 6 ) 用真空干燥浓缩机将上述洗脱液浓缩到约 500 μl。16000 r/min 离心 10 min,如果还有沉淀,取上清液,去沉淀。继续用真空干燥浓缩机浓缩样品到 50 μl,用含有 0.1% 甲酸的双蒸水稀释到 200 μl。
( 7 ) 用 300 μl 含有 0.1% 甲酸的 90% 乙腈溶液平衡 C18 Spec- Plus 固相萃取移液器吸头,然后用 300 μl 含有 0.1% 甲酸的双蒸水冲洗 5 次。
( 8 ) 吸取 200 μl 肽段溶液加样到已平衡好的 C18 Spec-Plus 固相萃取移液器吸头上,收集流出的液体,再重复慢速过柱两次(见注释 4) 。用 300 μl 含有 0.1% 甲酸的双蒸水冲洗柱子 5 次,然后用 300 μl 含有 0.1% 甲酸的 90% 乙腈溶液将肽段洗出。
( 9 ) 用真空干燥浓缩机将上述洗脱液浓缩到约 10 μl,此溶液可直接上样到双相 Mudpit 层析柱。
3.4 制备带喷雾发射器的二维(SCX/RP) 纳升级高效液相色谱层析柱
( 1 ) 层析柱的制备:将一根长 25 cm,内径为 100 μm,外径为 360 μm 熔融石英毛细管推入一个激光拉制仪中,留一截 3~8 μm 的熔融石英毛细管头部。这样它既可以用作离子源针头,也可用作连接到质谱仪进样口的层析柱 [ 25 ]。
( 2 ) 将装有悬浮在甲醇溶液里填充材料的微型离心管放入压力室中,并盖好盖。将毛细管的钝头用金属箍与上盖拧紧相连,深度与填充物质一致,拧紧金属箍后,气室加压到 500 psi,将悬浮在甲醇溶液中的填充材料推入到层析柱中,当填充材料被装填到毛细管的 3~8 μm 的尖头时,甲醇通过柱子流向其顶部,在毛细管中先装入 4 cm 强阳离子交换(SCX ) 填充物,然后再装入 8 cm 反相层析(C-18 ) 填充物。
( 3 ) 用 PEEK T 形管连接器将填充好的柱子与高效液相色谱(HPLC) 连接,这个 T 形管连接器的金线电极(与质谱仪的高压电源相连)为层析柱上游提供电压,与柱子的洗脱溶液形成液相连接。
( 4 ) 用 HPLC 缓冲液 B 洗层析柱 1 h,流速为 1 μl/min,使柱体填充物完全填实。
( 5 ) 在使用前,用 HPLC 缓冲液 A 平衡柱子 1h,流速为 1 μ/min。
3.5 二维纳升级高效液相色谱分离肽段
柱切换分离是一种在线分离方法,通过 HPLC 缓冲液连续洗脱双相柱,使洗脱液进入质谱仪,以确保在上样、盐洗脱和冲洗柱的过程中不丢失样品。第一相根据电荷性质分离肽段,第二相是根据疏水特性分离肽段。
( 1 ) 将 10 μl 样品注入 10 μl 自动进样环中,完成将肽段加载到强阳离子(SCX ) 柱床上(见注释 5) 。
a. 用 5% 缓冲液 B 以 10 μl/min 的流速注入进样环,将肽段推入自动进样环中,这个过程大约需要 25 min。
b. 然后将液流速度降至 400 nl/min,注入 35 min,将样品全部推入,并冲洗柱子。
c. 通过阳离子交换介质的任何肽段将结合到反相介质上,任何通过这两个树脂介质的肽段都将在质谱仪中被检测和破碎,全部的运行时间大约需要 70 min。
( 2 ) 用 5%~50% 的缓冲液 B 以 400 nl/min 的速度反相梯度洗脱 60 min。然后再用 50%~98% 的缓冲液 B 梯度洗脱 5 min,并用 98% 的缓冲液 B 洗脱 5 min,这样,残留的肽段都将被洗脱下来。用 5% 缓冲液 B 快速( 1 min ) 冲洗柱子,然后增加冲洗流速到 1 μl/min 冲洗柱子 24 min,重新平衡柱子,全部运行时间为 95 min ( 见注释 6) 。
( 3 ) 用 250 mmol/L 乙酸铵溶液逐步增加浓度洗脱 SCX 柱子 4 min,每次盐洗脱后都要伴随着反相梯度洗脱( 见步骤 2 中描述的),使离子交换介质中的多肽转移到反相介质中。那些松散结合在柱子上的肽段可在低浓度的缓冲液 C 中被转移,而结合紧密的肽段则需要更高浓度的缓冲液 C 或缓冲液 D。
a. 首先用 5% 的缓冲液 B 洗脱 5 min,流速为 400 μl/min。
b. 用 X% 的缓冲液 C 洗脱柱子 4 min,第一次盐洗脱中,X = 10%。
c. 用 5% 的缓冲液 B 洗脱柱子 7 min,然后用 5%~50% 缓冲液 B 的反相梯度洗脱 60 min。
d. 用 50%~98% 缓冲液 B 梯度洗脱柱子 5 min,再用 98% 缓冲液 B 洗脱 4 min 后,残留的肽段将被洗脱下来。
e. 用 5% 缓冲液 B 快速冲洗柱子,然后,增加到 1 μl/min 的流速持续冲洗 24 min,重新平衡柱子。
f. 之后用不同百分浓度(X = 20、30、40、50、60、70、80、90、100 ) 的缓冲液 C 分步洗脱柱子,每 10 步洗脱时间为 105 min。
( 4 ) 当 250 mmol/L 乙酸铵溶液盐洗脱结束后,最后一步盐洗脱是用 50% 的缓冲液 D 代替前面提及的 X% 缓冲液 C,以确保将所有紧密结合在 SCX 柱上的肽段转移到反相介质上。快速梯度变化洗脱以及用 98% 缓冲液 B 洗脱 20 min 可最大限度地将紧密结合在反相介质上的肽段洗脱下来。全部的运行时间为 105 min。表 21-1显示了步骤 3 和步骤 4 的层析过程。
3.6 运用 Thermo Electron 公司的高效液相色谱-离子阱质谱联用仪 LCQ DecaXP Plus 进行数据依赖性串联质谱分析
( 1 ) 仪器基本参数:质谱检测扫描范围:m/z 400~1500;5 次显微扫描,进样时间:500 ms,质谱信号灵敏度:1 X 105;裂解分离选择宽度:2.7 Da;肽段的默认携带电荷值:MS/MS=2; 喷雾电压:1.8 kV;动态排除: 7 min 窗口,重复计数= 2 , 记录时间=0.5 min;排除质量:低值 = 0.8 amu,峰值 = 1.5 amu;碰撞能量归一化 = 35%,激发 Q 值= 0.25,碰撞时间=30 ms;选择 3 个最强的离子按照 n= 3、2、1 的顺序用于裂解。
( 2 ) 使用这些参数设置,当程序设定读取从层析柱上洗脱下来的肽段的串联质谱信号 ,质谱仪就会连续不断地获得前面所述的 HPLC 中贯穿 13 个步骤的数据。动态排斥是为了确保肽段的丰度,以及与其相关的同位素没有被重复裂解,从而最大限度地分散选择裂解的不同肽段离子。
3.7 利用数据检索鉴定蛋白质
将无法阅读的串联质谱图谱在蛋白质序列数据库上检索比对,用以鉴定经蛋白酶消化后的肽段,用这些肽段的鉴定信息组装成蛋白质鉴定信息。
( 1 ) 用下列软件程序之一,将全套串联质谱在适当的蛋白质序列数据库中进行检索:
Sequest (Themo Hectron 公司) [26,27], Mascot (Matrix Sciences公司,London,UK ) [ 28,29] 或Xtandem ( 开放软件,可从马尼托巴蛋白质组学中心获取 http : " www. proteom& ca/opensource, html) 。

( 2 ) 在大多数生物样品的制备过程中存在许多的内源蛋白酶,所以在消化过程中也会出现非胰蛋白酶消化肽段。因此,最好在搜库设置参数时,不要特别指出全胰蛋白酶解肽段,这样可以避免明显的信息丢失。
( 3 ) 肽段鉴定数据需要排序和筛选,去除尽可能多的无关信息。遗憾的是,没有一种明确设定的标准能够保证从数据检索程序中输出的所有肽段是正确的,也无法排除不正确的肽段。一篇阐述数据检索参数的综述文章将告诉人们,在这个问题上几乎没有统一的意见。最好的办法是,在相同的实验室,使用相同的仪器设备,用已知的蛋白质消化样品,优化和改进一套公布的参数。肽段判断的准确性也可以通过搜索统计显著性评估 [ 32,33] 或通过重复检索一个反相蛋白序列数据库 [31,34,35 ] 来得以改善。
( 4 ) 一个仍存在争议的问题是, Mudpit 数据报告是否列入基于单一肽段鉴定的蛋白鉴定。一般情况下 Mudpit 实验中大约有一半的蛋白质鉴定是根据单一肽段信息鉴定出来的,所以这是一个很重要的需要考虑的问题。当然,一些蛋白质鉴定是非常准确的,因为一个小的蛋白质可能只有一个可用的胰蛋白酶水解肽段,或者一些修饰遮蔽了其他肽段的鉴定,或者虽然有许多胰蛋白酶水解的肽段产生,但是只有一个被正确地选择去裂解。此外,以单一肽段为基础的蛋白质鉴定可以在大多数 Mudpit 数据库中获得。数据库检索参数的微小变化会严重地影响搜索结果,产生假阳性鉴定的几率很高。蛋白质鉴定最好要报告基于两个或更多个肽段鉴定信息的蛋白质数量,以及两个不同的图谱包含单个肽段鉴定的数量 [36] ( 见 21.3.8) 。
3.8 结果举例:从成熟水稻中制备的叶片和根系组织的 Mudpit 分析
1. 植物的生长和收集水稻(Oryzasahm,cv. Nipponbare) 种子种在温室中,每天光照 12 h,控制 12 h 光照温度为 29°C,12 h 黑暗温度为 21°C,维持 30% 湿度,植物生长在含有 50% Sim-shine 混合土和 50% 硝基腐殖质土的小盆中,萌发 50 天后取叶片和根材料。
2. 蛋白质抽提、样品制备和 Mudpit 分析
用研钵将叶片和根在液氮中研磨成粉末。用 TCA/丙酮法抽提蛋白质(方法见 21. 3.1),用 3.2 和 3.3 的方法消化抽提得到的蛋白质,肽段混合物按照 3.4~3.7 中描述的方法进行分析。
3. 质谱数据库检索与分析
所有串联质谱数据比对搜索 NCBI 的公共资源中的一个水稻蛋白序列数据库,同时辅以一个包括胰蛋白酶、胞内蛋白酶赖氨酸-C、角蛋白、白蛋白、酪蛋白及其他普通实验室污染物的内在污染物文件。
用 Xtandem 软件检索数据,并用蛋白质组学全球分析机器网络工具(www.thegpmorg) 来分析数据。Xtandem软件检索参数的设置:碎片离子单一同位素质量误差:0.5 Da;母离子单一同位素质量误差:2.0士Da;频谱动态范围:100;频谱总峰:50;最大有效阈值 >0.1。氧化作用引起的 16 Da 的甲硫氨酸可变修饰是可以接受的。
4. 用 Mudpit 分析水稻叶片和根的实验结果表 21-2~ 表 21-4 显示了 Mudpit 分析水稻叶片和根的实验结果。每个实验鉴定出来的蛋白总数列在表 21-2中;分为 3 类:两个或更多个鉴定肽段;两个或更多个鉴定肽段或为一个预值小于 0.001 的鉴定肽段;预值小于 0.1 单个或多个鉴定肽段。这些鉴定蛋白质数量又被分为根和叶共有的,以及它们各自特有的几类。表 21-2 还包括了每个实验中检索到的 MS/MS 频谱数量的信息,以及上文描述的在每个分类项中肽段的数目。



这些实验结果清楚地说明了以下几点。
( 1 ) 在一次实验中,可以从一种植物组织材料中鉴定出数百个蛋白质。
( 2 ) 检索从两个实验中获得的所有超过 91000 MS/MS 的频谱,运用最低标准,我们在叶片中鉴定出 578 个蛋白质,根中鉴定出 538 个,其中包括 1005 个非冗余蛋白质鉴定。
( 3 ) 运用两个或多个鉴定肽段的更严格的标准后,这些数字分别缩减到 329、303 和 549。
( 4 ) 基于一个鉴定肽段的蛋白鉴定数量占总数的 43%,这与之前公布的数据集相符 (或略低于),这些数据集中百分数已被特别报道 [ 12,36,38] 。从这两个实验中鉴定出来的蛋白质数量是非常一致的,特别是当不把重复性在 Mudpit 分析技术作为重点考虑 Mudpi,但是,鉴定出来的非冗余蛋白质总数显示,在两个数据集中仅有 10% ~15% 的交叠,这正好说明蛋白质表达的组织特异性。
这些结果中另一个有趣的特征是,虽然在叶和根中鉴定出的蛋白质数量相似,但在叶片中鉴定到的肽段是根中的两倍以上。这是由于从叶片中鉴定出的大量肽段来自 RuBisCo 造成的,如表 21-3 所示。
表 21-3 列出通过 Mudpit 分析,从水稻叶片中鉴定到的前 25 个蛋白质,根据 Xtandem 蛋白质预值排序。表 21-4 列出通过 Mudpit 分析,从水稻根中鉴定到的前 25 个蛋白质,也是按照 Xtande 蛋白质预值排序。表 21-3和 表 21-4 中列出了在叶和根组织中含量最大的蛋白质,这些蛋白也是这些组织中主要的蛋白质,而且表达量很高 。叶片组织中存在许多 RuBisCo、ATP 合成酶、光系统蛋白复合物以及其他几种叶绿体特异蛋白的异构体。根中含有大量碳水化合物代谢酶,如蔗糖- UDP 葡糖基转移酶 2,磷酸丙糖异构酶,抗坏血酸过氧化物酶和三磷酸甘油醛脱氢酶。有趣的是:根中也包含一些可能在对土壤中生物和非生物胁迫响应机制中发挥重要作用的高水平表达病程相关蛋白。
( 1 ) 从植物的中部切取未衰老的绿色叶片,立即放入自封塑料袋中冷冻。如果没有冷冻设备,可先放在冰上,然后再放到 -20°C 保存。
( 2 ) 挖出植物根系,在绿色茎段以下一英寸的地方取材。抖动根系,并快速的依次放入 3 个大烧杯中洗去土壤,然后再放入自封塑料袋中冷冻,或暂时保存在冰上。
( 3 ) 称取 2.5 g 去除了茎秆和其他物质的冰冻叶片和根系,用预冷的剪刀剪碎样品后 ,放入预冷的陶瓷研钵中,加液氮研磨至粉末,需要多次添加液氮,以保持组织的冰冻状态。
( 4 ) 把冰冻的叶片或根系粉末放入 40 ml 离心管中,加入 25 ml 叶片重悬液,振荡混合,确保所有的粉末被重悬起来后,在 -20°C 下静置 45 min,再振荡摇匀,35000 g 离心 15 min。
( 5 ) 用玻璃移液管吸去上清液,注意不要扰动沉淀。用等体积的 EDTA 洗液洗涤沉淀。振荡打散沉淀,冰上静置 5 min,35000 g 离心 15 min。重复操作至少两次,直到叶片蛋白质沉淀不再有绿色。
( 6 ) 冰冻干燥沉淀物,得到含有蛋白质、细胞壁和纤维的淡褐色材料。
3.2 从三氯乙酸/丙酮沉淀的粉末中制备蛋白质样品
( 1 ) 针对每个样品,分别称取 20 mg 的三氯乙酸/丙酮沉淀粉末(制备方法见 21.3.1 ) 放入有盖的 1.5 ml 离心管中。
( 2 ) 在每只管中加入 1 ml 的 100 mmol/L Tris-HCl ( pH 8.5 ) ,涡旋振荡 1 min,18000 g 离心 10 min,弃上清液(见注释 1)。
( 3 ) 在每只管中加入 500 μl 的 8 mol/L 尿素,涡旋振荡 5 min,超声波水浴处理 10 min,然后旋转振荡 30 min。
( 4 ) 18000 g 离心 10 min,将约 400 μl,含蛋白质浓度为 0.1~0.5 μg/μl ( 见注释 2 ) 的上清液移至另一只管中。
( 5 ) 用 8 mol/L 尿素重复第 3 和第 4 步骤,合并上清液,调整容积到 600 μl。
3.3 抽提蛋白质的蛋白酶消化
( 1 ) 在总容积为 600 μl 的蛋白抽提液中添加 5 μl 外切赖氨酸蛋白酶工作液,在旋转振荡器上 37°C 消化过夜(见注释 3) 。
( 2 ) 在每个样品中分别加入 2300 μl 的 100 mmol/L 碳酸氢铵,30 μl 的 100 mmol/L 氯化钙,60 μl 的乙腈,10 μl 的胰蛋白酶工作液。终浓度为:1.6 mol/L 尿素,76 mmol/L 碳酸氢铵,1 mmol/L 氯化钙,2% ( V/V ) 乙腈,3.3 ng/L 胰蛋白酶。
( 3 ) 在旋转振荡器上 37°C 消化 24~48 h。添加 60 μl 甲酸使终浓度为 2%,将样品保存在 -20℃ 备用。
( 4 ) 用 15 ml 含有 0.1% 甲酸的 90% 乙腈溶液平衡 C18 SeP- Pak 层析柱,然后用 20 ml 含有 0.1% 甲酸的双蒸水清洗柱子 4 次。
( 5 ) 吸取 3 ml 蛋白酶消化液加样到已平衡好的 C18 Sep-Pak 层析柱上,收集流出的液体,再重复慢速过柱两次。用 20 ml 含有 0.1% 甲酸的双蒸水洗柱子,洗脱盐及其他松散结合物质。再用 3 ml 含有 0.1% 的甲酸的 90% 乙腈溶液将肽段从 C18 Sep-Pak 柱上洗脱下来。
( 6 ) 用真空干燥浓缩机将上述洗脱液浓缩到约 500 μl。16000 r/min 离心 10 min,如果还有沉淀,取上清液,去沉淀。继续用真空干燥浓缩机浓缩样品到 50 μl,用含有 0.1% 甲酸的双蒸水稀释到 200 μl。
( 7 ) 用 300 μl 含有 0.1% 甲酸的 90% 乙腈溶液平衡 C18 Spec- Plus 固相萃取移液器吸头,然后用 300 μl 含有 0.1% 甲酸的双蒸水冲洗 5 次。
( 8 ) 吸取 200 μl 肽段溶液加样到已平衡好的 C18 Spec-Plus 固相萃取移液器吸头上,收集流出的液体,再重复慢速过柱两次(见注释 4) 。用 300 μl 含有 0.1% 甲酸的双蒸水冲洗柱子 5 次,然后用 300 μl 含有 0.1% 甲酸的 90% 乙腈溶液将肽段洗出。
( 9 ) 用真空干燥浓缩机将上述洗脱液浓缩到约 10 μl,此溶液可直接上样到双相 Mudpit 层析柱。
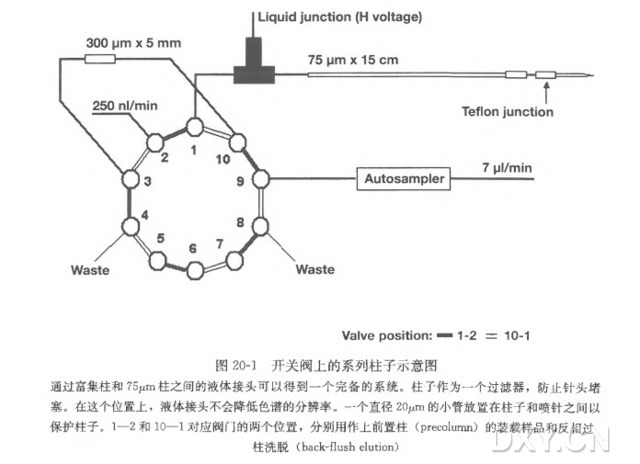
3.4 制备带喷雾发射器的二维(SCX/RP) 纳升级高效液相色谱层析柱
( 1 ) 层析柱的制备:将一根长 25 cm,内径为 100 μm,外径为 360 μm 熔融石英毛细管推入一个激光拉制仪中,留一截 3~8 μm 的熔融石英毛细管头部。这样它既可以用作离子源针头,也可用作连接到质谱仪进样口的层析柱 [ 25 ]。
( 2 ) 将装有悬浮在甲醇溶液里填充材料的微型离心管放入压力室中,并盖好盖。将毛细管的钝头用金属箍与上盖拧紧相连,深度与填充物质一致,拧紧金属箍后,气室加压到 500 psi,将悬浮在甲醇溶液中的填充材料推入到层析柱中,当填充材料被装填到毛细管的 3~8 μm 的尖头时,甲醇通过柱子流向其顶部,在毛细管中先装入 4 cm 强阳离子交换(SCX ) 填充物,然后再装入 8 cm 反相层析(C-18 ) 填充物。
( 3 ) 用 PEEK T 形管连接器将填充好的柱子与高效液相色谱(HPLC) 连接,这个 T 形管连接器的金线电极(与质谱仪的高压电源相连)为层析柱上游提供电压,与柱子的洗脱溶液形成液相连接。
( 4 ) 用 HPLC 缓冲液 B 洗层析柱 1 h,流速为 1 μl/min,使柱体填充物完全填实。
( 5 ) 在使用前,用 HPLC 缓冲液 A 平衡柱子 1h,流速为 1 μ/min。
3.5 二维纳升级高效液相色谱分离肽段
柱切换分离是一种在线分离方法,通过 HPLC 缓冲液连续洗脱双相柱,使洗脱液进入质谱仪,以确保在上样、盐洗脱和冲洗柱的过程中不丢失样品。第一相根据电荷性质分离肽段,第二相是根据疏水特性分离肽段。
( 1 ) 将 10 μl 样品注入 10 μl 自动进样环中,完成将肽段加载到强阳离子(SCX ) 柱床上(见注释 5) 。
a. 用 5% 缓冲液 B 以 10 μl/min 的流速注入进样环,将肽段推入自动进样环中,这个过程大约需要 25 min。
b. 然后将液流速度降至 400 nl/min,注入 35 min,将样品全部推入,并冲洗柱子。
c. 通过阳离子交换介质的任何肽段将结合到反相介质上,任何通过这两个树脂介质的肽段都将在质谱仪中被检测和破碎,全部的运行时间大约需要 70 min。
( 2 ) 用 5%~50% 的缓冲液 B 以 400 nl/min 的速度反相梯度洗脱 60 min。然后再用 50%~98% 的缓冲液 B 梯度洗脱 5 min,并用 98% 的缓冲液 B 洗脱 5 min,这样,残留的肽段都将被洗脱下来。用 5% 缓冲液 B 快速( 1 min ) 冲洗柱子,然后增加冲洗流速到 1 μl/min 冲洗柱子 24 min,重新平衡柱子,全部运行时间为 95 min ( 见注释 6) 。
( 3 ) 用 250 mmol/L 乙酸铵溶液逐步增加浓度洗脱 SCX 柱子 4 min,每次盐洗脱后都要伴随着反相梯度洗脱( 见步骤 2 中描述的),使离子交换介质中的多肽转移到反相介质中。那些松散结合在柱子上的肽段可在低浓度的缓冲液 C 中被转移,而结合紧密的肽段则需要更高浓度的缓冲液 C 或缓冲液 D。
a. 首先用 5% 的缓冲液 B 洗脱 5 min,流速为 400 μl/min。
b. 用 X% 的缓冲液 C 洗脱柱子 4 min,第一次盐洗脱中,X = 10%。
c. 用 5% 的缓冲液 B 洗脱柱子 7 min,然后用 5%~50% 缓冲液 B 的反相梯度洗脱 60 min。
d. 用 50%~98% 缓冲液 B 梯度洗脱柱子 5 min,再用 98% 缓冲液 B 洗脱 4 min 后,残留的肽段将被洗脱下来。
e. 用 5% 缓冲液 B 快速冲洗柱子,然后,增加到 1 μl/min 的流速持续冲洗 24 min,重新平衡柱子。
f. 之后用不同百分浓度(X = 20、30、40、50、60、70、80、90、100 ) 的缓冲液 C 分步洗脱柱子,每 10 步洗脱时间为 105 min。
( 4 ) 当 250 mmol/L 乙酸铵溶液盐洗脱结束后,最后一步盐洗脱是用 50% 的缓冲液 D 代替前面提及的 X% 缓冲液 C,以确保将所有紧密结合在 SCX 柱上的肽段转移到反相介质上。快速梯度变化洗脱以及用 98% 缓冲液 B 洗脱 20 min 可最大限度地将紧密结合在反相介质上的肽段洗脱下来。全部的运行时间为 105 min。表 21-1显示了步骤 3 和步骤 4 的层析过程。
3.6 运用 Thermo Electron 公司的高效液相色谱-离子阱质谱联用仪 LCQ DecaXP Plus 进行数据依赖性串联质谱分析
( 1 ) 仪器基本参数:质谱检测扫描范围:m/z 400~1500;5 次显微扫描,进样时间:500 ms,质谱信号灵敏度:1 X 105;裂解分离选择宽度:2.7 Da;肽段的默认携带电荷值:MS/MS=2; 喷雾电压:1.8 kV;动态排除: 7 min 窗口,重复计数= 2 , 记录时间=0.5 min;排除质量:低值 = 0.8 amu,峰值 = 1.5 amu;碰撞能量归一化 = 35%,激发 Q 值= 0.25,碰撞时间=30 ms;选择 3 个最强的离子按照 n= 3、2、1 的顺序用于裂解。
( 2 ) 使用这些参数设置,当程序设定读取从层析柱上洗脱下来的肽段的串联质谱信号 ,质谱仪就会连续不断地获得前面所述的 HPLC 中贯穿 13 个步骤的数据。动态排斥是为了确保肽段的丰度,以及与其相关的同位素没有被重复裂解,从而最大限度地分散选择裂解的不同肽段离子。
3.7 利用数据检索鉴定蛋白质
将无法阅读的串联质谱图谱在蛋白质序列数据库上检索比对,用以鉴定经蛋白酶消化后的肽段,用这些肽段的鉴定信息组装成蛋白质鉴定信息。
( 1 ) 用下列软件程序之一,将全套串联质谱在适当的蛋白质序列数据库中进行检索:
Sequest (Themo Hectron 公司) [26,27], Mascot (Matrix Sciences公司,London,UK ) [ 28,29] 或Xtandem ( 开放软件,可从马尼托巴蛋白质组学中心获取 http : " www. proteom& ca/opensource, html) 。
( 2 ) 在大多数生物样品的制备过程中存在许多的内源蛋白酶,所以在消化过程中也会出现非胰蛋白酶消化肽段。因此,最好在搜库设置参数时,不要特别指出全胰蛋白酶解肽段,这样可以避免明显的信息丢失。
( 3 ) 肽段鉴定数据需要排序和筛选,去除尽可能多的无关信息。遗憾的是,没有一种明确设定的标准能够保证从数据检索程序中输出的所有肽段是正确的,也无法排除不正确的肽段。一篇阐述数据检索参数的综述文章将告诉人们,在这个问题上几乎没有统一的意见。最好的办法是,在相同的实验室,使用相同的仪器设备,用已知的蛋白质消化样品,优化和改进一套公布的参数。肽段判断的准确性也可以通过搜索统计显著性评估 [ 32,33] 或通过重复检索一个反相蛋白序列数据库 [31,34,35 ] 来得以改善。
( 4 ) 一个仍存在争议的问题是, Mudpit 数据报告是否列入基于单一肽段鉴定的蛋白鉴定。一般情况下 Mudpit 实验中大约有一半的蛋白质鉴定是根据单一肽段信息鉴定出来的,所以这是一个很重要的需要考虑的问题。当然,一些蛋白质鉴定是非常准确的,因为一个小的蛋白质可能只有一个可用的胰蛋白酶水解肽段,或者一些修饰遮蔽了其他肽段的鉴定,或者虽然有许多胰蛋白酶水解的肽段产生,但是只有一个被正确地选择去裂解。此外,以单一肽段为基础的蛋白质鉴定可以在大多数 Mudpit 数据库中获得。数据库检索参数的微小变化会严重地影响搜索结果,产生假阳性鉴定的几率很高。蛋白质鉴定最好要报告基于两个或更多个肽段鉴定信息的蛋白质数量,以及两个不同的图谱包含单个肽段鉴定的数量 [36] ( 见 21.3.8) 。
3.8 结果举例:从成熟水稻中制备的叶片和根系组织的 Mudpit 分析
1. 植物的生长和收集水稻(Oryzasahm,cv. Nipponbare) 种子种在温室中,每天光照 12 h,控制 12 h 光照温度为 29°C,12 h 黑暗温度为 21°C,维持 30% 湿度,植物生长在含有 50% Sim-shine 混合土和 50% 硝基腐殖质土的小盆中,萌发 50 天后取叶片和根材料。
2. 蛋白质抽提、样品制备和 Mudpit 分析
用研钵将叶片和根在液氮中研磨成粉末。用 TCA/丙酮法抽提蛋白质(方法见 21. 3.1),用 3.2 和 3.3 的方法消化抽提得到的蛋白质,肽段混合物按照 3.4~3.7 中描述的方法进行分析。
3. 质谱数据库检索与分析
所有串联质谱数据比对搜索 NCBI 的公共资源中的一个水稻蛋白序列数据库,同时辅以一个包括胰蛋白酶、胞内蛋白酶赖氨酸-C、角蛋白、白蛋白、酪蛋白及其他普通实验室污染物的内在污染物文件。
用 Xtandem 软件检索数据,并用蛋白质组学全球分析机器网络工具(www.thegpmorg) 来分析数据。Xtandem软件检索参数的设置:碎片离子单一同位素质量误差:0.5 Da;母离子单一同位素质量误差:2.0士Da;频谱动态范围:100;频谱总峰:50;最大有效阈值 >0.1。氧化作用引起的 16 Da 的甲硫氨酸可变修饰是可以接受的。
4. 用 Mudpit 分析水稻叶片和根的实验结果表 21-2~ 表 21-4 显示了 Mudpit 分析水稻叶片和根的实验结果。每个实验鉴定出来的蛋白总数列在表 21-2中;分为 3 类:两个或更多个鉴定肽段;两个或更多个鉴定肽段或为一个预值小于 0.001 的鉴定肽段;预值小于 0.1 单个或多个鉴定肽段。这些鉴定蛋白质数量又被分为根和叶共有的,以及它们各自特有的几类。表 21-2 还包括了每个实验中检索到的 MS/MS 频谱数量的信息,以及上文描述的在每个分类项中肽段的数目。
这些实验结果清楚地说明了以下几点。
( 1 ) 在一次实验中,可以从一种植物组织材料中鉴定出数百个蛋白质。
( 2 ) 检索从两个实验中获得的所有超过 91000 MS/MS 的频谱,运用最低标准,我们在叶片中鉴定出 578 个蛋白质,根中鉴定出 538 个,其中包括 1005 个非冗余蛋白质鉴定。
( 3 ) 运用两个或多个鉴定肽段的更严格的标准后,这些数字分别缩减到 329、303 和 549。
( 4 ) 基于一个鉴定肽段的蛋白鉴定数量占总数的 43%,这与之前公布的数据集相符 (或略低于),这些数据集中百分数已被特别报道 [ 12,36,38] 。从这两个实验中鉴定出来的蛋白质数量是非常一致的,特别是当不把重复性在 Mudpit 分析技术作为重点考虑 Mudpi,但是,鉴定出来的非冗余蛋白质总数显示,在两个数据集中仅有 10% ~15% 的交叠,这正好说明蛋白质表达的组织特异性。
这些结果中另一个有趣的特征是,虽然在叶和根中鉴定出的蛋白质数量相似,但在叶片中鉴定到的肽段是根中的两倍以上。这是由于从叶片中鉴定出的大量肽段来自 RuBisCo 造成的,如表 21-3 所示。
表 21-3 列出通过 Mudpit 分析,从水稻叶片中鉴定到的前 25 个蛋白质,根据 Xtandem 蛋白质预值排序。表 21-4 列出通过 Mudpit 分析,从水稻根中鉴定到的前 25 个蛋白质,也是按照 Xtande 蛋白质预值排序。表 21-3和 表 21-4 中列出了在叶和根组织中含量最大的蛋白质,这些蛋白也是这些组织中主要的蛋白质,而且表达量很高 。叶片组织中存在许多 RuBisCo、ATP 合成酶、光系统蛋白复合物以及其他几种叶绿体特异蛋白的异构体。根中含有大量碳水化合物代谢酶,如蔗糖- UDP 葡糖基转移酶 2,磷酸丙糖异构酶,抗坏血酸过氧化物酶和三磷酸甘油醛脱氢酶。有趣的是:根中也包含一些可能在对土壤中生物和非生物胁迫响应机制中发挥重要作用的高水平表达病程相关蛋白。
来源:丁香实验