【样本估算】帮你搞定临床调查中的样本量计算!
科研论文时间
如何计算临床调查中样本量?
统计老师说:针对不同的数据属性,可以根据已知的临床信息,采用相应的估算公式完成样本量估算或者借助相应的统计学软件完成这一过程。
然而,他是统计老师。我们大部分人的统计都比较渣渣……

图片来源:时景璞. 临床研究中样本量的估计方法 [J]. 中国组织工程研究, 2003, 7(10):1569-1571.
碰到上图类似的公式几乎是「崩溃」的节奏!有次我们医院准备调研员工对新的绩效改革方案的满意度,院长大手一挥,每个人都填!!!所有人!!!

可以看出我们院长的「豪气」,也能看出我们院长的统计学也很渣。这其实是临床调研中最极端的做法是搞全面调查 (普查),虽然没有了抽样误差,但是总误差可能比抽样调查更大。
为什么这样说呢?
因为普查涉及范围大,时间长,调查人员多,许多条件无法控制,因此,调查实施时就可能比较粗糙,在数据录入、处理时也更容易产生误差,特别是过大规模的抽样调查更容易发生类似的情况。
而精心设计和实施的适当规模的抽样调查,则可以做得比较细致,数据处理时也比较容易控制误差。还有过大规模的调查必定耗时过长,待所收集的资料发表之时可能已失去其大部分价值了。
临床科研者常见困惑
但是,临床科研中样本含量的估计是一个很复杂的问题,要清楚地说明各种情况下样本含量估计的方法和原理也十分不易。很多临床人员的科研路就是从读不懂样本量计算公式开始的。
目前由于不同书籍介绍的计算公式不尽一致,以至同一结果的计算可能有一定的差别,这一点应引起注意。因此我们今天抛开统计的角度跟大家说说如何在获得调查研究合适的样本量?
方法一:survey monkey(调查猴子)
估计很多人都听说过 survey monkey 的功能非常强大、界面友好不仅可以样本量计算还能处理数据,于是很多人去找度娘搜索「survey monkey」
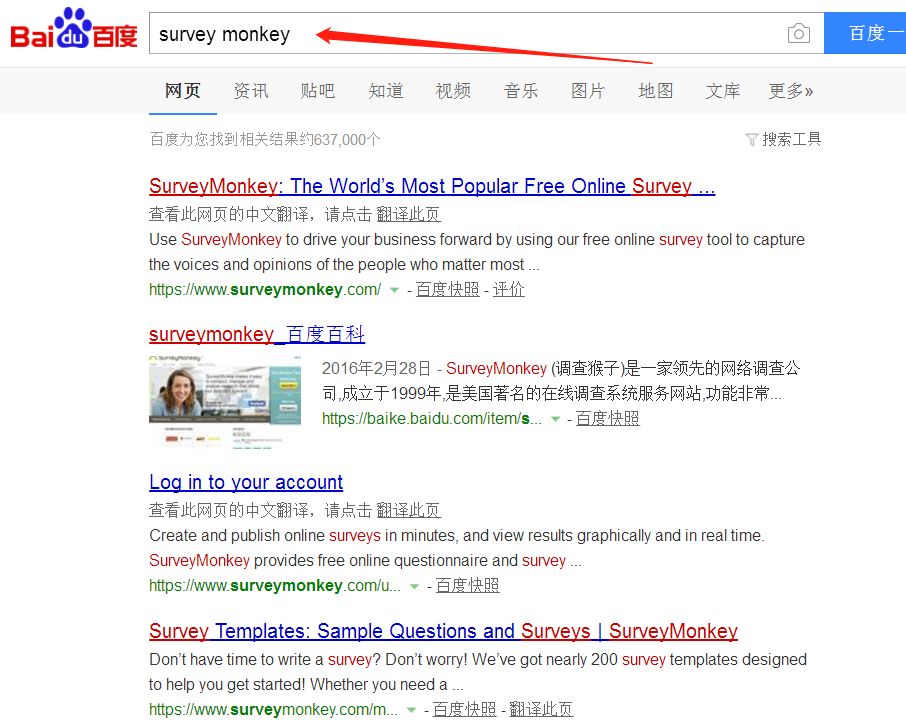
然而「too young,too simple」(图样图森破),点开后的界面可能是这样的!
很多人即使注册了也找不到样本量计算的公式,其实样本量的计算公式不应该这样度娘,搜索词应该换成「survey monkey sample size calculator」。
开后很快就能看到我们想要的网站了!
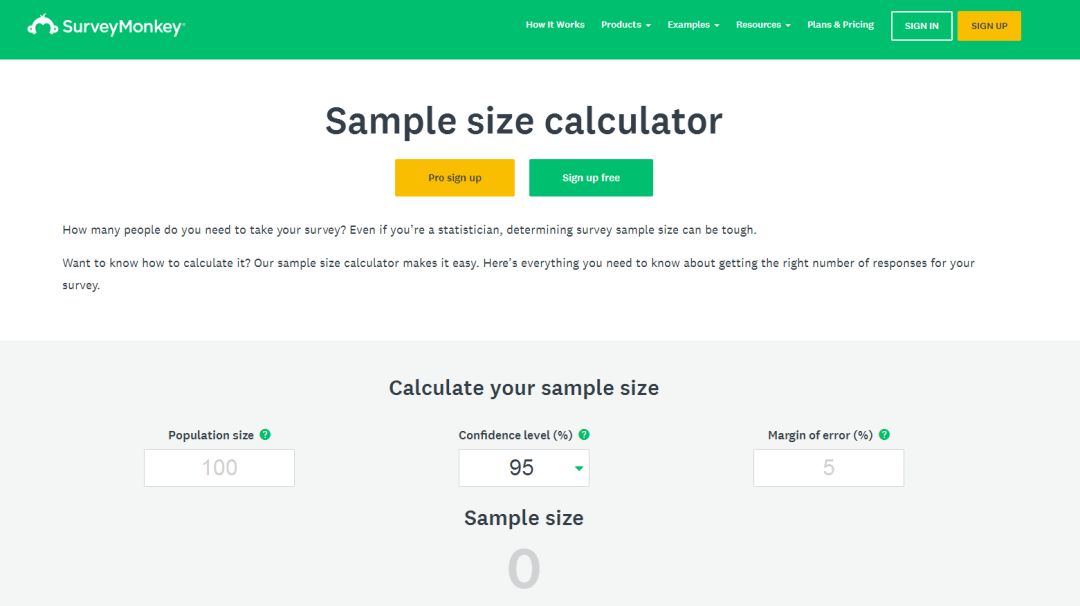
接下来就开始我们的调查,比如说我们还是以我们「豪气」院长调查员工绩效满意这件事情来计算样本量,如何开展呢?
第一步:我们需要知道「Population size 」(总体大小)
打个比方我们医院正好有 3000 人,则在第一个框框里输入 3000。
第二步:Confidence level (%),可信区间。
关于他的官方解释是这样的:95% 可信区间,意味着如果你用同样的步骤,去选样本,计算可信区间,那么 100 次这样的独立过程,有 95% 的概率你计算出来的区间会包含真实参数值,即大概会有 95 个可信区间会包含真值。

很多人看完官方解释依然很蒙!
其实我们可以举个简单的例子,刮刮乐,你买一张和买 10 张中奖的几率是不是不一样?很显然买 10 张刮刮乐中奖几率更高一些,我们就可以说 10 张刮刮乐的区间命中率更高,(但是成本也高,风险降低),这就是区间的简单版本解释!
关于为什么是 95 是基于以均值 μ^ 为中心的概率为 0.95 的区域为(基于高斯分布)而得出来的,假如真的对这些东西不感冒,就记住一个规律,可信区间范围越大,样本量越大,我们调查研究最常用的是 95% 的可信区间。
第三步:Margin of error (%),误差范围
这是的意思是由于受到统计方法和被调查者人数的限制,常会出现与真实值的误差。
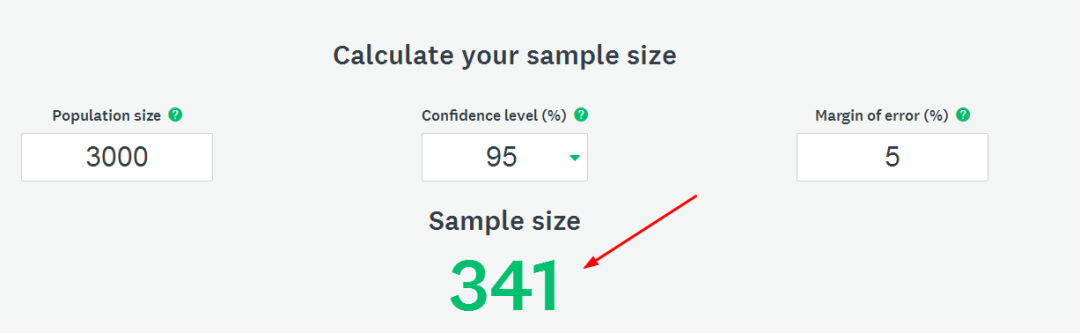
只要误差幅度控制在一定范围内,统计数据就是有效的。我们目前大部分把把该值设置为 5%,那么我们就会得出一个 341 的样本,也就是我们院长本次随机调查 341 名即可得到关于绩效满意度真实的数据!
方法二:中文版调查小工具
目前国内也有很多跟调查猴子很类似的小工具,也非常实用,大家可以自己去度娘搜素「样本量计算网站」等,就会出来很多,找到合适自己的研究就好,计算的准确度和调查猴子没有什么区别,只是界面给人的感觉不是那么舒适,比如下面这个!
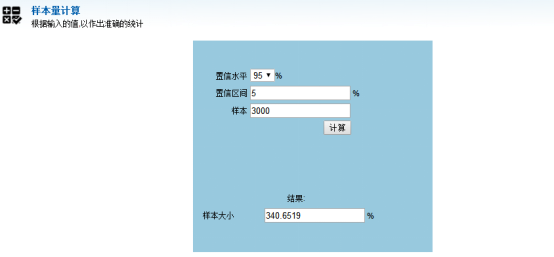
网址 http://tool.520101.com/calculator/yangbenliang/
丁香科研精品技能课 1 分钱学
内含外泌体、SCI 写作、文献检索
综述指导教学等海量科研课
👇👇👇