DNA重组技术及其在基因诊断中的应用-- 工具酶
互联网
第二十三章 DNA重组技术及其在基因诊断中的应用
第一节 工具酶
基因工程的基本技术是人工进行基因的剪切、拼接、组合。基因是一段具有一定功能的DNA分子,要把不同基因的DNA线形分子片段准确地切出来,需要各种限制性核酸内切酶(restriction endonuclease);要把不同片段连接起来,需要DNA连接酶(ligase);要结合基因或其中的一个片段,需要DNA酶(DNa polymerase)等。因此,酶是DNA重组技术中必不可少的工具,基因工程中所要用的酶统称为工具酶。
一、DNA限制性内切酶
Lurva和Human(1952)以及Bertani和Weigle(1953)发现了噬菌体λ的限制作用,即用一种λ噬菌体在一种宿主细胞生长良好,但在另一种宿主细胞中生长很差,其原因在于它的DNA受到后一种宿主的“限制”。由此发现了限制-修饰系统。
各种细菌都能合成一种或几种顺序专一的核酸内切酶。这些酶切割DNA的双链,因为它们的功能就是切割DNA,限制外源性DNA存在于自身细胞内,所以称这种核酸内切酶为限制酶。合成限制酶的细胞自身的DNA可以不受这种酶的作用,因为细胞还合成了一种修饰酶,它改变了限制酶识别的DNA顺序的结构,使限制酶不能起作用。限制-修饰系统是细胞的一种防卫手段。如果用噬菌体去感染限制-修饰系统有活性的细菌,噬菌体DNA没有先经修饰,它与先经修饰的噬菌体相比,感染效率要低几个数量级。未经修饰的噬菌体DNA进入细胞后被限制酶切成片段,片段的数目与DNA分子中限制酶的识别点数目成正比,这些片段进一步被细胞的核酸外切酶降解,就会开始裂解感染,由此产生的子代噬菌体全部带有修饰过的DNA,因此能以很高的效率去感染另一些具有相同限制-修饰系统的细菌。目前,从各种生物中分离出的限制性内切酶已超过175种,其中80多种是切割DNA双链。
(一)命名原则
限制性内切酶主要是从原核生物中提取的。现在通用的命名原则是:第一个字是细菌属名的第一个字母,第二、三个字是细菌种名的前二个字母,这些字母都用斜体字母;接下去是细菌株的第一个字母,用正体字母书写。如果同一菌株中有几种不同的内切酶时,则分别用罗马数字Ⅰ、Ⅱ、Ⅲ……来代表。现在列表举例说明如下(表23-1)。
表23-1 几种限制性内切酶命名原则举例
细菌原名 细菌种名 菌株名称 限制酶名称 Arthrobacter Luteus AluⅠ Bacillus amyloliquefaciens H BamHⅠ Escherichia Coli RY13 EcoRⅠ Haemophilus influeuzae Rd HindⅢ(二)分类和特性
限制性内切酶主要分成三大类。第一类限制性内切酶能识别专一的核苷酸顺序,并在识别点附近的一些核苷酸上切割DNA分子中的双链,但是切割的核苷酸顺序没有专一性,是随机的。这类限制性内切酶在DNA重组技术或基因工程中没有多大用处,无法用于分析DNA结构或克隆基因。这类酶如EcoB、EcoK等。
第二类限制性内切酶能识别专一的核苷酸顺序,并在该顺序内的固定位置上切割双链。由于这类限制性内切酶的识别和切割的核苷酸都是专一的。所以总能得到同样核苷酸顺序的DNA片段,并能构建来自不同 基因组 的DNA片段,形成杂合DNA分子。因此,这种限制性内切酶是DNA重组技术中最常用的工具酶之一。这种酶识别的专一核苷酸顺序最常见的是4个或6个核苷酸,少数也有识别5个核苷酸以及7个、9个、10个和11个核苷酸的。如果识别位置在DNA分子中分布是随机的,则识别4个核苷酸的限制性内切酶每隔46(4096)个核苷酸就有一个切点。人的单倍体基因组据估计为3×199核苷酸,识别4个核苷酸的限制性内切酶的切点将有(3×109/2.5×102)约107个切点,也就是可被这种酶切成107片段,识别6个核苷酸的限制性内切酶也将有(3×109/4×103)约106个切点。
第二类限制性内切酶的识别顺序是一个回文对称顺序,即有一个中心对称轴,从这个轴朝二个方向“读”都完全相同。这种酶的切割可以有两种方式。一是交错切割,结果形成两条单链末端,这种末端的核苷酸顺序是互补的,可形成氢键,所以称为粘性末端。如EcoRI的识别顺序为:
↓ |
5’……GAA | TTC……3’
3’……CTT | AAG……5’
| ↑
垂直虚线表示中心对称轴,从两侧“读”核苷酸顺序都是GAATTC或CTTAAG,这就是回文顺序(palindrome)。实线剪头表示在双链上交错切割的位置,切割后生成5’……G和AATTC……3’、3’……CTTAA和G……5’二个DNA片段,各有一个单链末端,二条单链是互补的,可通过形成氢键而“粘合”。另一种是在同一位置上切割双链,产生平头末端。例如HaeⅢ的识别位置是:
↓
5’……GG↓CC……3’
3’……CC↓GG……’
↑
在箭头所指处切割,产生的两个DNA片段是:
5’……GG CC……3’
和
3’……CC GG……5’
有时候两种限制性内切酶的识别核苷酸顺序和切割位置都相同,差别只在于当识别顺序中有甲基化的核苷酸时,一种限制性内切酶可以切割,另一种则不能。例如HpaⅡ和MspⅠ的识别顺序都是5’……GCGG……3’,如果其中有5’-甲基胞嘧啶,则只有HpaⅡ能够切割。这些有相同切点的酶称为同切酶或异源同工酶(isoschizomer)。
第三类限制性内切酶也有专一的识别顺序,但不是对称的回文顺序。它在识别顺序旁边几个核苷酸对的固定位置上切割双链。但这几个核苷酸对则是任意的。因此,这种限制性内切酶切割后产生的一定长度DNA片段,具有各种单链末端。这对于克隆基因或克隆DNA片段没有多大用处。
二、甲基化酶
细胞的限制-修饰系统中的修饰作用是由甲基化酶(methylase)来完成的。甲基化酶同限制性内切酶具有完全相同的识别顺序。甲基化酶使识别顺序中的某个碱基发生甲基化,保护DNA不被限制性内切酶切开。
真核生物中目前只发现5-甲基胞嘧啶(M5C)。M5C占整个胞嘧啶中的2~7%(果蝇和某些昆虫例外)。M5C大多以M5CpG的形式存在,不同物种或同一物种的不同组织中,M5C出现的频率也不尽相同。目前已经纯化作为商品出售的甲基化酶见表23-2。
将限制性内切酶和甲基化酶同时作用,可使有几种可能识别顺序的限制性内切酶只对其中一种识别顺序有效。例如限制性内切酶AvaⅠ的识别顺序是:
5’……CPyCGPuG……3’
3’……GPuGCPyC……5’
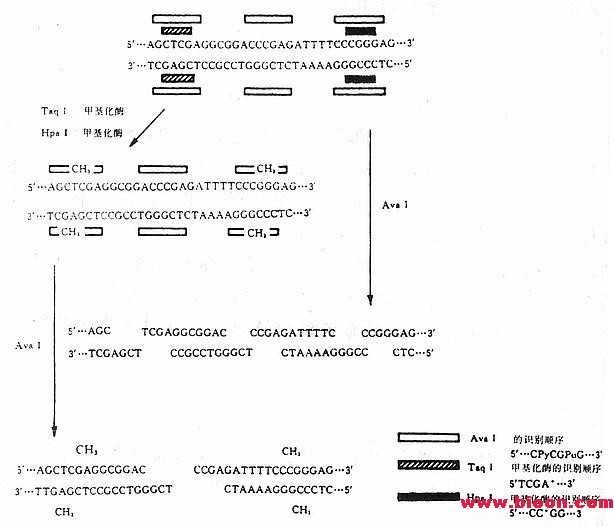
Py可以是任何一种嘧啶,pu可以是任何一种嘌呤。因此可以有4种识别顺序。如果同时使用甲基化酶TaqⅠ和甲基化酶HpaⅡ,则AvaⅠ的识别顺序将只是5’……CCCGAG……3’。现用图解说明(图23-1)。
如果有一个DNA片段,有AvaⅠ的3个识别顺序,当用AvaⅠ处理后可得4个片段。可是,如果先用TaqⅠ甲基化酶和HpaⅡ甲基化酶使DNA顺序中的有些碱基甲基化,然后再用AvaⅠ去切,结果只有1个识别顺序可被AvaⅠ作用,只产生2个DNA片段。
甲基化的碱基 AluⅠ 5’……AGundefinedT……3’ BamHⅠ 5’……GGATundefinedC……3’ ClaⅠ 5’……ATCGundefinedT……3’ damⅠ 5’……GundefinedTC……3’ EcoRⅠ 5’……GAA