基因数据分析的主流软件
互联网
相关专题
基因组测序
在过去的几年中,许多生物的基因组完成了测序工作,如何对如此庞大的原始序列信息进行分析和应用,正是现在最为棘手的问题。大量的基因预测软件和在线工具应运而生。如何广泛而深入地了解并能有的放矢地利用这些工具,已经成为21世纪分子生物学家的必修课。
随着大规模EST和cDNA序列信息的获取,那些基于表达序列同源范围的程序,在基因组注释中的作用日益显著。即使在稀少基因或组织特异性表达的基因中,基因组序列的相关性信息也颇具参考价值。所以利用基因组序列的比对来扩充基因的信息是不可获缺的。特别是在对人类基因组做注释时,与那些相对完整的脊椎动物基因组,如小鼠和鱼类的基因组比较是必不可少的步骤。
许多基因组测序计划正在进行之中,尽管仍存在急需解决的问题,比较基因组学方法(comparative genome approach)被认为是最有应用前景的方法。该方法不仅在基因预测中举足轻重,而且在鉴定调控基因、探索垃圾基因(junk gene)等方面的作用也不容忽视。基因预测软件的用户应该认识到,软件预测结果的可靠性和置信水平都有较大程度的提升。但这些毕竟是预测的结果,分子生物学家,总是试图证明真实存在的蛋白质,及其功能和在组织中的表达状态。
当前,已有超过60种真核基因组测序计划在进程之中。然而生物学方面的相关注释还远不能匹配如此汹涌而至的原始序列数据。当务之急是,研发出更多的准确而快速的分析工具,特别在寻找基因、确定其准确功能等应用方面。许多基因预测程序都可以免费共享。当前,几乎没有一个完美的程序可以解决用户们的所有问题。这就需要用户最大程度地利用主流程序的整合优势。
基因数目预测的主流软件
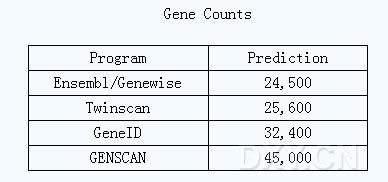
10年前,研究人员开始预测人类基因的数目,这个数目在很长时间没有明显改变。几年前,最多的预测是100,000;当人类基因组完成测序时,这个数目降至30,000。现在有降至20,000左右。研究人员相信:充分考虑人类的基因组序列和其它生物的基因组序列,可以做出近似的估计。Affymetrix 的计算科学家David Kulp称:“很难对基因数目的诸多估算,做出正误的判别。”分子生物学家正在寻找比预期设想的基因更小的基因。在某种情况下,就一段编码的序列,很难确定是一个基因或是两个基因的重叠。学术界仍不能完全肯定地归类那些编码多种蛋白质的基因,或是仅编码RNA的类似基因的序列。
早在20世纪30年代,George Beadle和Tatum认为每个基因仅仅编码一个蛋白质。几十年来这个说法仍旧沿袭。现在则认为这样的理论过于简单。一个基因可以编译成多种蛋白质,甚至可以转录成RNA。人类基因组中编码蛋白质的区域,称为外显子,约仅占总体DNA的2%。一些简单的基因仅含有一个外显子。有些基因没有功能,称为假基因pseudogene:是与已知基因在不同部位有密切相似性的基因,但由于结构上有加入或缺失,而阻止了正常的转录或翻译,以致使它们无功能。这样就会增加基因预测的数量,造成许多假阳性的结果。
英国剑桥的EBI(European Bioinformatics Institute)的基因预测专家Ewan Birney指出:“目前预测的人类24,500个基因中,有将近3,000个基因可能为pseudogene”。华盛顿大学的计算科学家Michael Brent称:“如果在基因预测中准确地考虑到假基因的存在,那么预测的结果会更为精确。”
目前广泛应用的基因预测方法是:“ab initio”方法,即通过探索DNA序列中特异的区域,如基因的起始区域和终止区域,来进行基因预测。另一种方法是比较基因组学的方法,即根据与已知的蛋白质或基因之间的相似性来发现新的基因。Ab initio程序对于那些类似于基因的序列,也给予归类,所以总的预测数量要高出实际值;而比较的方法不考虑无相似关系的基因,所以估计的基因数目偏低。
大多数人所熟知的一个ab initio程序叫做Gene Modeler是1990年新墨西哥洲大学的Chris Fields和Cari Soderlund研发的。当时是被应用在线虫Caenorhabditis elegans的基因探寻过程中。那时出现的其它软件都稍逊于Gene Modeler。例如,BLAST、FASTA能将DNA序列翻译成蛋白质序列,并与已有的、蛋白质数据进行比较。
这个领域进展迅速,涌现出许多具有专业软件编写技能的预测人员,包括采用Gene Modeler的方法创建GeneID来寻找人类基因的Guigo,以及编写GeneParser软件的Eric Snyder。GeneParser采用了一个称为动力学程序的技术,将外显子与不编码蛋白质的内含子区分开来。Rockville的TIGR(The Institute for Genomic Research)的Steven Salzberg自从1994年,利用ab initio的方法,来改进寻找人类基因的程序。
随后的几年里,他们又研发出几个新的程序。其中的一个是与更为详尽的背景信息相整合,进行基因预测。它可以更加清楚地预测外显子和内含子的大小。另一个程序是同时作用于两个完整的基因组,由计算机完成两者的比较。许多研究人员更倾向于后种方法,原因是相似的物种,更为倾向于拥有相似的基因序列。National Human Genome Research Institute的遗传学家Eric Green说,他及他的同事,已经从13个物种中进行了DNA比较,包括狗、牛、鸡以及河豚鱼。2003年8月14日的Nature上发表了他们对基因、以及调控区域的比较结果。
GENSCAN就是一个经典的基因预测软件。1996年由MIT的Chris Burge开始编写这个软件程序。当时,Burge的许多同事主张采用比较的方法,他们随机选取一个最新测序基因组中基因的DNA序列,与数据库中已存在的基因进行联配。但是Chris Burge认为:“利用人类基因组所获知的信息,可能不能发现某些新的基因。” 他还积极吸取了加州大学计算机科学家David Haussler的经验。很多年前,Haussler就意识到基因预测的问题与语言学家们所遇到的问题相类似。语言学家总是试图寻找语言中句法、语法,以及其它某些特征。
Haussler和其他人都建议从语言学中借助一种叫做Hidden Markov Model,HMM隐马尔科夫模型的统计工具。在序列分析中,HMM通常是多重序列对位排列的概率模型,但也可用于单一序列的周期性模式的模型,比如代表发现基因外显子的模式。在一个多重序列对位排列的模型中,用被称作状态的符号的概率分布代表排列中的每一列字母,插入和缺失用其他状态表示。然后在模型内沿特定的路径从一个状态进入另一个状态,试图匹配一条给定的序列。从每一状态选出下一个匹配符号,记录其概率(频率)和从前一状态进入特定状态的概率(过渡态概率)。
状态与过渡态的概率相乘就得到给定序列的概率。一般来说,HMM是一个对给定字符的统计模型,类似随机状态机器,从每一个状态过渡到另一个就产生一个字符。状态间的过渡态用过渡概率确定。HMM已成为许多基因预测算法的标准。Burge指出:目前存在一整套的能够区分部分基因的模式和规则。比如,几乎所有的基因在起始和终止区域存在特异的序列。外显子的末端通常也存在一个特征序列,可以指导相关的酶切除外显子下游的内含子。Burge已经利用这些规则分析了几百个已知外显子和内含子位置的基因序列。
GENSCAN是进行基因预测的首选工具。但是,即使最好的预测软件也存在不足之处。GENSCAN就过分估算了基因数目。它的预测结果是人类基因组中有45,000个基因,相当于现在普遍认可数目的两倍。Burge承认GENSCAN确实存在问题,但他认为太多的基因总比太少要好。对于过剩的预测,用户可以积极去除假阳性的结果。Burge称:GENSCAN可能不能预测基因的准确数目,但从人类和其它物种的基因数据分析中所得到的新的序列,可以进一步完善GENSCAN。他还指出,如果能继续开展基因的探寻工作,他会更倾向于选用比较学的方法。
其他程序,如GeneSweep、Ensembl/Genewise,则是基于对数据进行组装来寻找基因。但是它们比早期的比较学方法更为成熟。Genewise是Birney和他的同事,从已知的蛋白质序列着手进行基因分析的程序。这些蛋白质都来自已知氨基酸序列的蛋白质家族,具有保守的DNA序列。蛋白质或多或少的相类似。利用这些蛋白质家族组装起来所形成的优势,计算机就能比较来自同种或不同个体已知的蛋白质序列和新的蛋白质序列。随着更多的物种基因组被测序,比较整个基因组,而不是比较那些相对短小的序列,正逐渐变为现实。A
ffymetrix公司的Kulp称:现在整合这些比较的方法来预测基因,已经成为最具应用前景的研究路线。并且众多的应用程序都融合了多元策略进行基因预测。

基因序列分析的主流软件
在一定的精度范围内,利用生物信息学的方法和软件对目标基因的基本特征进行分析,能够让分子生物学家更为迅速和全面地发现基因的特征,了解基因在生命体中的真实结构和功能,从而为大规模地开展基因的后续分析奠定基石。
核苷酸序列中蕴涵着丰富的信息,对于编码基因序列的分析,主要是围绕如下内容进行:寻找开放读码框、预测基因功能、分析选择性剪切方式、分析基因多态性位点、分析基因表达调控区域、统计序列GC含量、追踪密码子使用偏向性、设计应用于目的基因的酶切位点和引物等,寻找基因的开放读码框:基因的开放读码框(Open Reading Frame),包含从5’端翻译起始密码子(ATG)到终止密码子(TAA、TAG、TGA)之间的一段编码蛋白质的碱基序列。开放阅读框的预测程序主要是针对编码区的特征进行统计、以及相关模式的识别或是利用同源比对的识别方法。现在较为主流的程序是GetOrf、ORFFinder、Plotorf,就是专门识别ORF的有利工具。一些功能强大的软件如:GENSCAN、GRAIL = 2 \_ROMAN_II、GENEMARK、GlimmerM除进行ORF的分子外,还可对多种基因的结构特征进行分析。专业人员常用的软件还有:Genefinder、Genehunter、FGeneSH、FGeneSB、FGeneSV、Generation、BCM Gene Finder、Genebuilder等。其中GlimmerM和FGeneSB更适与原核生物的基因预测。
外显子和内含子剪切位点的分析:在真核生物中基因的外显子和内含子长度不一,但剪切供体和受体的位点具有相当程度的保守性。所谓的供体位点(donor)是基因内含子5’端GU的位置;受体位点(acceptor)是内含子3’端AG的位置。对于mRNA或cDNA序列的分析是通过比对相关的基因组序列,来进行结构分析。例如,Spidey(是NCBI开发的工具软件),Sim4,BLAST等程序。NetGene2和Splice View可以提供编码区核苷酸序列剪切位点的直接预测。
分析基因的选择性剪切:基因的选择性剪切机制(Alternative splicing):真核基因转录成前体mRNA后,还要进一步改装成成熟的mRNA。许多基因并不是一次全部切除其内含子,而是在不同的细胞、或不同的发育阶段,选择性地剪切其内含子,从而生成不同的mRNA。随着数据库中数据信息的指数增加,目前运用生物信息学的工具对基因产物的选择性剪切,也能开展较为详尽的分析。众多的选择性剪切机制数据库,可利用http://scholar.google.com/进行在线搜索。较为流行的如:ProSplicer就是基于蛋白质、mRNA、EST序列的选择性剪切数据库。
分析基因的表达调控区域:基因组中全部基因的表达,都遵循严整而精确的调控机制。基因的调控区域序列相关特征的深入分析,为全面了解基因的功能提供丰富的数据基础。
⑴脊椎动物的5’端的启动子周围是CpG岛,它是寻找基因的重要线索。EMBL提供的CpG岛的计算工具是:CpGPlot/CpGReport/Isochore。CpG Island和CpG promoter也是较为常用的工具。
⑵对基因的核心启动子、转录因子结合位点、转录起始位点的识别:可充分利用TRRD、TransFac、MIRAGE、EPD等在线基因调控区域的数据库;Softberry软件集团http://www.softberry.com/推出的:BPROM、TSSP、TSSG、TSSW等软件也值得使用。
⑶预测转录终止的信息:使用的工具是Hcpolya。
⑷分析密码子的使用偏性:有DOS运行界面的CodenW、SYCO、CHIP、Codon usage。
⑸分析限制性核酸内切酶位点:WEB Cutter、CUTTER、TACG interface、Watcut、NEB cutter、Digest等。
核苷酸序列综合分析软件:用户通常需要对目的基因进行多重分析,所以将序列拼接、基因序列的组分分析、编码区域预测、序列比对、引物设计、酶切位点预测等多项独立的分析加以整合的综合分析软件应运而生。目前有GeneBuilder、DNA Tool、SEQ tools、DNAssist、GeneTool、DNAman、DNA Strider、p DRAW32、gene-explorer等。GeneBuiler就是多模块单独执行功能的基因结构预测系统(Gene Structure Prediction System)。
新数据的获得驱动着软件的研发。目前现有的海量数据库,它们的质量和特征差异悬殊,仍需进行继续完善。London-based online的出版商BioMed Central的数据编辑Matthew Day称:“目前还没有较为理想的公共数据库集合群,服务于所有不同研究领域生物学工作者。所有的数据都应具备友好的用户界面,并与期刊数据库相链接。那时每个生物学者都可以畅快淋漓地享受数据汪洋的航行。”
在基因组时代,那些小的实验室很容易感到滞后性。相比之下,规模较大的生物技术公司,现在仅在一个下午完成的工作,对于中型的实验室可能要耗费数月之久。但是生物信息软件技术将专业的数据分析知识和技术,全部压缩到密集的程序集中。事实证明,这些软件的应用前景将更加广泛,操作界面也日趋简化,运行的结果更易于注释。崭新的在线服务和软件产品,让枯燥无味的数据分析变得妙趣横生。