




非甩锅!论文出现硬伤,责任真不在我
生物学霸
223
『老师,我用论文里给的序列,实验失败一个月了。』
『再好好做做吧。』
『您说,论文里的序列不会是错的吧……』
『……』
——《论实验失败的第N种可能》
看到这,大家应该知道,今天要聊些啥了,是的,就是论文中那些本应该正确的基因序列,却因为某些原因出错了!
8 月 4 日,Nature 的新闻版块在线发表了一篇文章,谈到了一个大家平时可能忽略的问题,也就论文中出现的基因序列可能是错误的。

具体而言,报道中提到的错误是我们常说的『文不对题』,即一个功能基因对应的序列并不是正确的,而这样的错误,却发生在超过 700 项研究论文中。
论文中的序列错误或将影响数百项研究的准确性
根据 Nature 的报道,在对近 12000 篇人类遗传学论文进行计算机辅助分析后研究人员发现,700 多项研究在论文中呈现的 DNA 或 RNA 试剂的序列中存在错误,这表明一部分关于人类功能基因的研究是不可靠的,甚至有可能指向故意为之的学术造假。

上述研究目前发布在预印本平台 BioRxiv 上,接下来就让我们进一步走进这篇论文,看看这些存在错误基因序列的研究们是个啥情况。

根据论文,研究人员开发了一种半自动筛选工具 Seek & Blastn 来对论文中所用核苷酸试剂的序列进行检查,共计检查了 11799 篇出版物,在 78 种期刊中确定了 712 篇论文,这些论文描述了至少一个被识别出存在错误的核苷酸序列。
在这项研究中,研究者将论文分为5个语料库(SGK、miR-145、Cisplatin + Gemcitabine、Gene 和 Oncology Reports),针对 17 个人类基因(ADAM8、ANXA1、EAG1、GPR137、ICT1、KLF8、 MACC1,MYO6,NOB1,PP4R1,PP5,PPM1D,RPS15A,TCTN1,TPD52L2,USP39 和 ZFX)进行了研究。
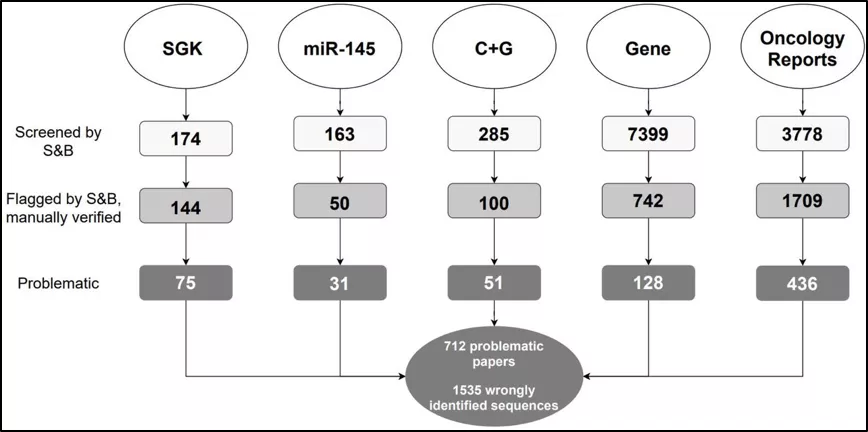
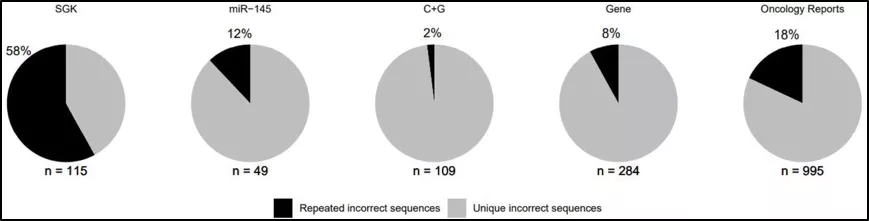
研究人员在先前的研究中就发现了一些频繁出错的核苷酸序列,这些存在错误序列的论文大都研究了在癌细胞中敲除单个人类基因对于癌细胞系的影响,故而他们将这些论文命名为单基因敲除论文(SKG)。
有趣的是,在单基因敲除论文这个大类中,存在许多的重复性序列错误,而大多数(159 / 174, 91%)SGK 论文由中国大陆作者发表,几乎所有论文都隶属于医院(147 / 159, 92%)。
图片来源:BioRxiv
如此高的比例,不禁让人想入非非啊。
诚实的错误,还是故意为之
看到这,相信很多胖友都想问出这个问题:是学术造假吗?
大家心里或许都有个答案。
但是论文的作者 Byrne 指出:
有些问题可能是无意的错误。但是研究人员发现了许多不太可能是诚实错误的不准确之处,甚至用于 PCR 反应的序列不针对任何已知的人类基因或者序列。

研究人员还谈到:
我们发现的具有不正确核苷酸序列的人类基因功能论文的比例高得令人无法接受,这对旨在将基因组学研究转化为为患者治疗的研究领域构成了重大挑战。
进一步,研究者指出,分析中标记的许多有问题的论文的作者都隶属于中国医院,而在过去的两年中,多起中国医院与论文工厂的学术丑闻让 Byrne 怀疑她的团队发现的一些论文也可能来自论文工厂。

上述的种种迹象表明,或许一部分论文真的来自于论文工厂,毕竟出自论文工厂的论文大都存在共通之处,比如那些雷同的标题结构,这也就不难解释为啥单基因敲除这类有固定形式的论文里问题论文的比例较高了。
不论是诚实的错误,还是故意为之的造假,这类容易被检出的错误在未来显然会得到更严格的质量控制,因为一些期刊已经向编辑建议他们可以使用 Seek & Blastn 来检查提交稿件中核苷酸序列的错误。
笔者诚信的大家,肯定是不会造假的,但是一个大家常用的软件也会造成论文中基因名字的错误。
Excel 和基因名称的相爱相杀
是的,大家没看错,就是那个大家日常在用的 Excel。
2016 年,一篇发表在 Genome Biology 上的论文指出,使用 Excel 制作补充文件的研究有五分之一都存在基因名称的错误。

而这一错误也并不复杂,当科学家在他们的表格中输入『SEPT2』和『MARCH1』时,Excel 认为他们指的是 9 月 2 日和 3 月 1 日,并贴心地帮他们将输入的字符转换为『2-Sept』和『1-Mar』,但事实上,SEPT2 指的是编码新型骨架蛋白 septin 2 的基因,而 MARCH1 指的是编码 E3 泛素连接酶的基因。
直到去年的这个时候,国际人类基因组组织下辖的基因命名委员会终于忍耐不住,将上述两个基因改名,MARCH1 将变为 MARCHF1,SEPT1 变为 SEPTIN1。

而这次针对软件问题对基因名称及命名规则进行的修改在总体上也收到了正面的反馈,尽管有些人认为应该让微软去修复『bug』。
但话说回来,科研人员在使用Excel的人群中只是很小的一部分,对于基因名称可能的出错,我们更应该做的是更认真的核对。
不管是诚实的错误,还是故意为之的错误,论文最正确的模样,不应该是不出错吗?










