R 语言的高颜值的配图法则 | 论文写作
丁香园
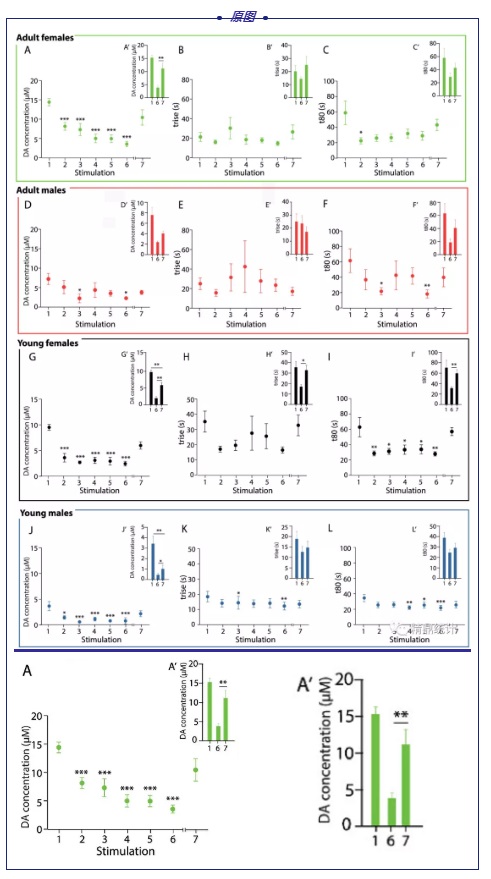
笔者前一段时间忙于为新文章制作配图,多处搜集配图优雅美观的优质论文。最后终于找到一篇发表在 Science Advances 的文章——通过高通量测序分析揭示了小 RNA 在小鼠卵母细胞和早期胚胎中的调控作用。

文章中除了复杂的 RNA Seq、Chip Seq 分析,图表的搭配十分美观。虽说我们是崇高的科(ke)学 (yan) 家 (gou),但关乎我们毕业大计的 SCI 也得要「高颜值」。
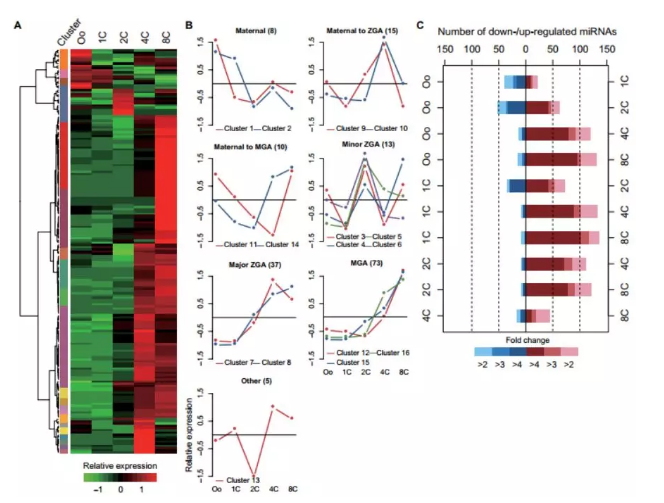
以常见的热图(heatmap)为例,在分子生物学涉及高通量以及芯片的文章中,尤其是 RNA-seq 相关论文里,热图是文章里经常出现的数据可视化形式。
一张美观的热图不仅可以直观呈现多样本、多个基因的全局表达量变化,以及多样本或多基因表达量的聚类关系,更是如下图般令人赏心悦目。
绘制热图有多种方法,常见的大家有用 MeV,各种网页工具,甚至有用 Excel 再上手 PS 的。可是小伙伴们,21 世纪连小学生都会编程了,你咋还在用软件做热图?
且不说用 Excel 出来的热图截图清晰度能不能达到发文章的标准,先来看看它的美观度,笔者在这里随机打开一个数据集,利用色阶给大家用 Excel 做一下热图,效果如下:

What?这完全没有办法聚类好么,我还怎么看差异变化?把这样的热图给老板,别说文章凉了,能不能走出老板办公室都是问题。

图片来源:影视截图
现在的高分论文一个个华丽丽的配图,动辄 R 语言、Python…听起来就高级,笔者当年凭着中学的记忆笨笨地操作 Excel,真是苦不堪言!
老板说了,要是再做不出来满意的图,就滚去刷一个月锥形瓶。
于是就有小伙伴问了,没时间系统地学习编程,那种「套代码公式就能搞定 R 语言绘图,懂中文就能会的教程」,能不能给我来一份啊?
答案是肯定的了,下面就跟随笔者,从作图小白一步步做个初级大触吧~
1 基本图绘制
呐~笔者整理出一份基础教程,为了照顾零基础的电脑盲同学,我们从安装 R 语言开始介绍。给大家两个网址,里面详细介绍了 R 语言 [2] 和 RStudio [3] 的安装。
安装好后我们打开 RStudio:
> setwd("D:/workdir/") #设置工作目录
>install.packages(“ggplot2”) #安装 pheatmap 程序包
> library(ggplot2) #加载 ggplot2 程序包
> data <- read.csv("text.csv",header = T,row.names = 1) #读取数据,读取 csv 格式数据,header = T 代表首行为表头,row.names = 1 代表首列为行名。
笔者找来一个数据集如下:
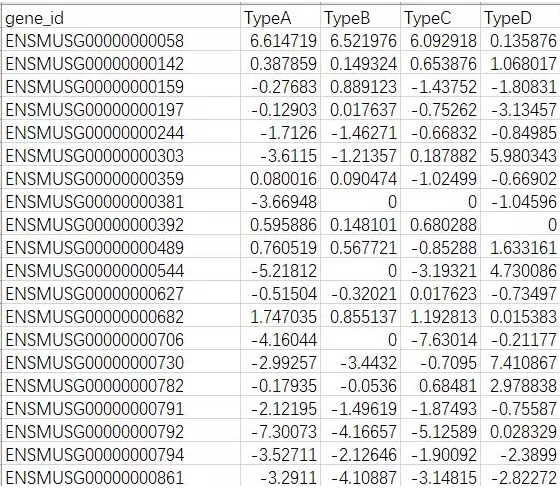
进行完准备工作后,我们开始学习,基本图的制作:
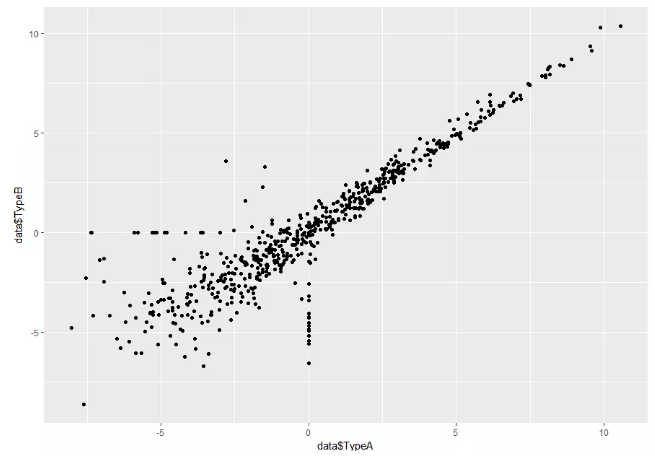
(1)散点图
> p <- ggplot(data,aes(x=data$TypeA,y=data$TypeB)) + geom_point() # data 代表数据名,aes(x=data$TypeA,y=data$TypeB) 代表横坐标与纵坐标,geom_point() 可以表示绘制散点
> p #展示结果图
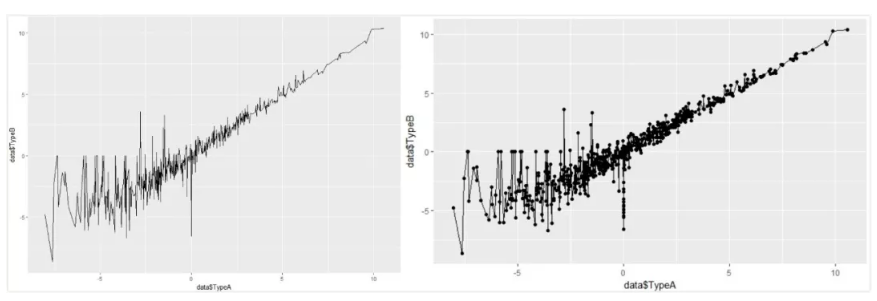
(2)折线图
> p <- ggplot(data,aes(x=data$TypeA,y=data$TypeB)) + geom_line() + geom_point() # geom_line() 代表绘制折线,geom_point() 存在与否可以表示点的标注。
> p
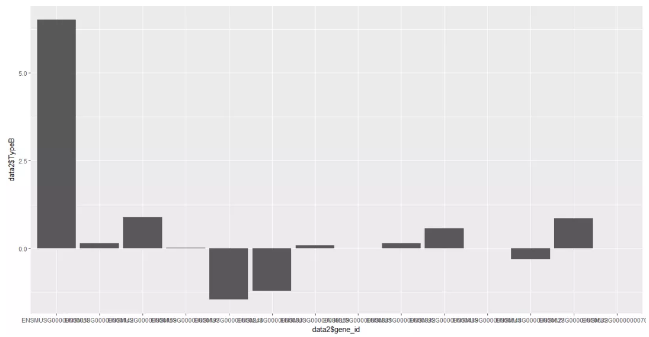
(3)条形图 (为了更直观,笔者截取了部分数据)
> p <- ggplot(data,aes(x=data$gene_id,y=data$TypeB)) + geom_bar(stat = "identity") # geom_bar() 代表绘制直方图。
> p
(4)箱线图
> p <- ggplot(data3,aes(x=data3$Type,y=data3$data)) + geom_boxplot() # geom_boxplot() 代表绘制箱线图。
> p
(5)小提琴图
> p <- ggplot(data3,aes(x=data3$Type,y=data3$data)) + geom_violin() # geom_violin() 代表绘制小提琴图。
> p
至此,笔者给大家带来五种基本图的绘制,还是简单的吧~
2 基本图修饰
通过上面的学习,我们大致了解基本图的绘制,所有的修饰都建立这些图形之上,这部分给大家说说如何让基本图更「高大上」,通过基本图的修饰,我们就能完成大部分的配图模仿了。
(1)配色
对于笔者这样直男审美的大汉来说,有一个华丽丽的配色包可谓是莫大的福利,那么 R 语言中是否有一个这样的配色包呢?
有的,那就是 RColorBrewer。
按照前文的方式我们配置好工作目录,加载好数据以及 ggplot2、RColorBrewer 程序包。
> display.brewer.all() #用这个命令可以生成一张图查看本程序的调色板,如下图所示:

> p <- ggplot(data1,aes(x=data1$number1,y=data1$stage2,color=data1$stage,shape=data1$value)) +scale_color_brewer(palette = "Blues") +geom_point()# color=data1$stage 将颜色属性传递给 stage 这一列,shape=data1$value 将形状属性传递给 value 这一列,scale_color_brewer(palette = "Blues") 使用上图中 Blues 调色板。
> p
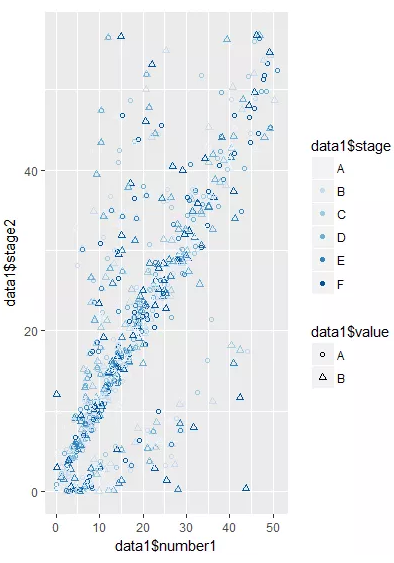
(2)坐标轴
坐标轴文本修饰可以更加清晰的按照作者的意愿表达,文章中的配图坐标轴都有明显的修饰痕迹:

坐标轴修饰也是通过一些基本完成命令,以修改上图为例:
> p + coord_flip() #交换 x 轴和 y 轴
> p + ylim(0,15) #如果想截取某一段可以用此命令设置值域。
> p + scale_x_continuous(breaks =seq(18,34,50) ) #设置刻度线位置
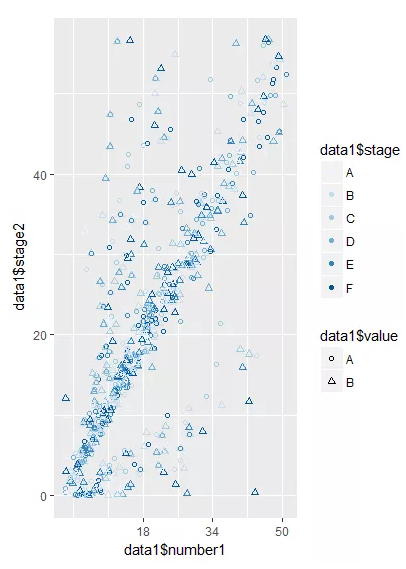
> p + theme(axis.text.x = element_text(angle = 90,family = "Times",face = "italic",colour = "darkred",size=rel(0.9))) # angle = 90 设置字体角度, family = "Times" 设置字体族, face = "italic" 设置样式, colour = "darkred" 设置颜色, size=rel(0.9) 设置大小
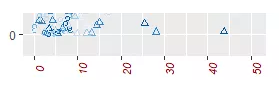
> p + xlab("Number of data") #修改坐标文本
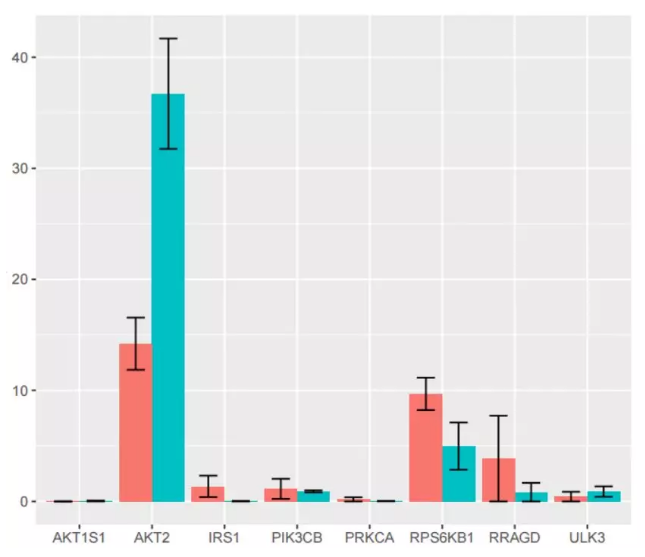
(3)误差线修饰
文章中使用了大量的误差线条形图:
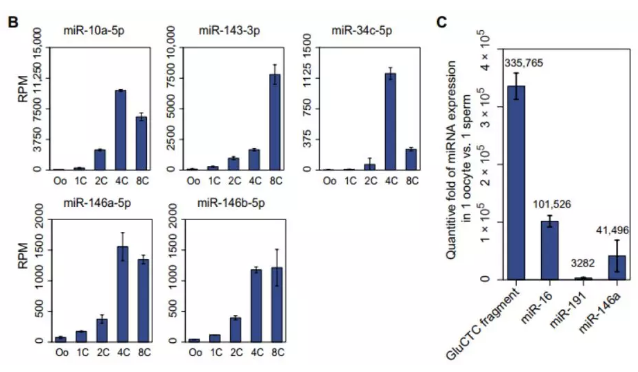
误差线是大家经常需要的通常用于显示潜在的误差或相对于系列中每个数据标志的不确定程度。误差线可以用标准差 (平均偏差) 或标准误差, 用以下这个命令可以为图表添加误差线:
p <- ggplot(data1,aes(x=data1$gene,y=data1$FPKM,fill=data1$stage)) #读取数据
+ geom_bar(position = "dodge", stat = "identity") #设置条形图 [position = "dodge"] 代表条形图成簇状分布
+ geom_errorbar(aes(ymin=data1$FPKM-data1$Standard.Deviation, ymax=data1$FPKM+data1$Standard.Deviation), width=.5,position=position_dodge(.9)) #增加误差线,误差线高度为 FPKM ±Standard.Deviation 两列数据都是提前计算好的。
(4)基本属性扩展
主题更改:我们利用基础图形命令得到下图:
> p <- ggplot(heightweight,aes(x=ageYear,y=heightIn,colour=sex)) + geom_point()
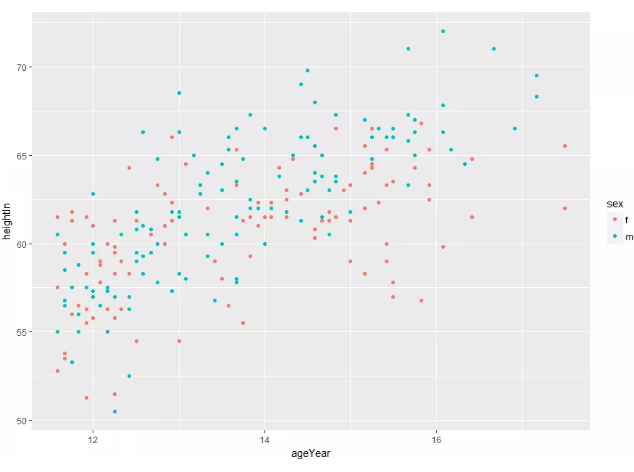
下面对外观进行修整:
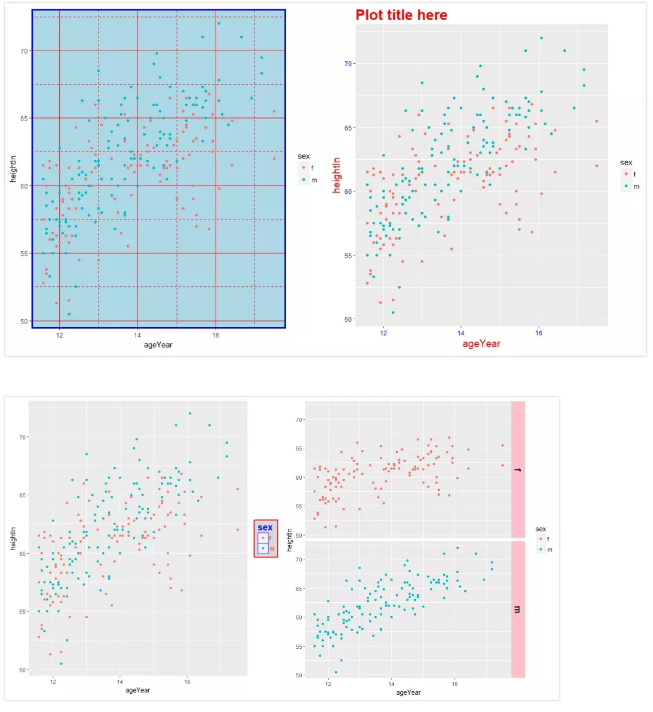
①绘图区域选项
> p + theme(panel.grid.major = element_line("red"),panel.grid.minor = element_line(colour = "red",linetype="dashed",size=0.2),panel.background = element_rect(fill="lightblue"),panel.border = element_rect(colour = "blue",fill=NA,size=2)) # panel.grid.minor = element_line(colour = "red",linetype="dashed",size=0.2) 割线颜色,type,尺寸;panel.background = element_rect(fill="lightblue") 背景颜色,panel.border = element_
②文本项目选项
> p + ggtitle("Plot title here") + theme(axis.title.x = element_text(colour="red",size=14),axis.text.x = element_text(colour="blue"),axis.title.y = element_text(colour ="red",size=14,angle=90),axis.text.y=element_text(colour="blue"),plot.title=element_text(colour="red",size=20,face="bold")) # ggtitle("Plot title here") 标题选项;theme 主题选项,其余为文字选项。
③图例选项
> p + theme(legend.background = element_rect(fill="grey85",colour = "red",size=1),legend.title = element_text(colour = "blue",face="bold",size = 14),legend.text = element_text(colour = "red"),legend.key = element_rect(colour = "blue",size = 0.25))
④分面选项
> p + facet_grid(sex ~ .) + theme(strip.background = element_rect(fill="pink"),strip.text.y = element_text(size = 14,angle = -90,face = "bold"))
实操结果如下:
到此为止我们已经可以处理较为复杂的代码了,不信你试试模仿下文章中那个高级条形图?
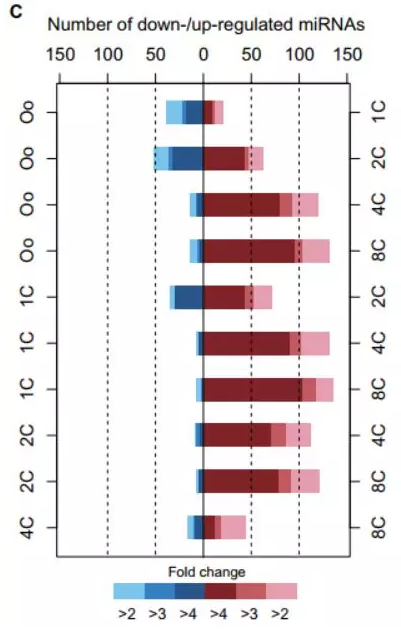
本次的学习大家也可以运用 R 语言绘制这样的图形,一个超长的函数也可以简单的拆分成几个小命令:
> p <- ggplot(data1,aes(x=data1$value,y=data1$number1,fill=data1$stage)) #写入数据
+geom_bar(stat = "identity",width = 0.6,alpha=.9) #柱状图基本设置
+ guides(fill=guide_legend(reverse = T)) #图例设置
+coord_flip() #反转坐标
+ theme_bw() + theme(panel.grid.major = element_blank(),panel.grid.minor = element_blank()) + geom_hline(aes(yintercept = 0), data1,alpha=0.2) #设置主题
+ labs(fill="Fold change") +ylab("Picture of text") #坐标标题
+scale_x_discrete(breaks = c("A","B","C","D","E","F"),labels = c("D0","D1,"D2,"D3,"D4,"D5)) #更换刻度文本
+ expand_limits(y=-300) #扩大值域
+ scale_y_continuous(breaks = c(-300,-200,-100,0,100,200,300)) #增加刻度线
+scale_fill_manual (values =c("p"="#3399CC","k"="#996666","4"="#802326","3"="#c2595e","2"="#e49eaf","1.5"="#FFCCCC","-4"="#29568a","-3"="#367fc2","-2"="#79c3ec","-1.5"="#99CCFF")) #更改配色方案
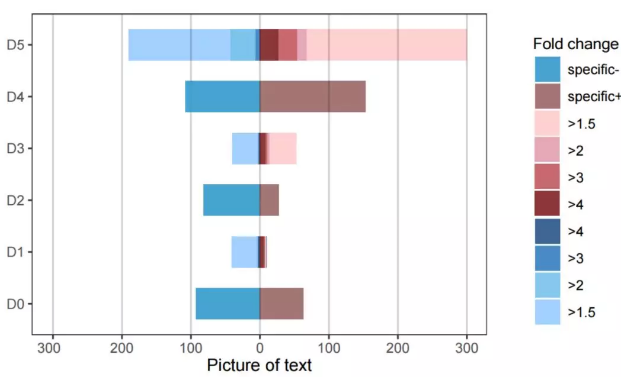
到此为止相信大家可以轻松运用 R 语言绘制基本图以及进行常规修饰了,终于可以和那些野鸡绘图方式说拜拜了。

图片来源:影视截图
什么?觉得还是不够用?经过两个阶段的艰苦奋战,大家的绘图之路已经爬完大半程,接下来小编将给大家带来 R 语言的高级绘图。那我们废话少说,继续满满的干货之路。
3 高级图绘制
(1)基因热图
文章中运用了大量的热图,热图在高通量分析文章中是必不可少的:
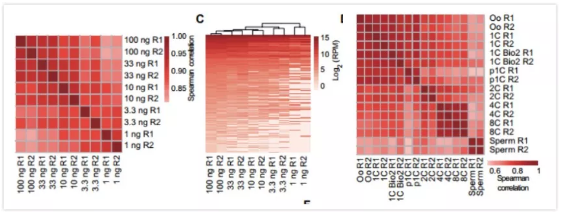
关于基因热图还真是让人又爱又恨,这部分将使用专门的热图绘制工具给大家讲解:
第一步:我们要安装并加载绘制热图的程序包
>install.packages(“pheatmap”) #安装 pheatmap 程序包
>library(pheatmap) #加载 pheatmap 程序包
第二步:设置工作目录,也就是要分析的文件所在的位置
>setwd("D:/") #我把文件放在 D 盘,大家根据自己的情况设置
第三步:读取文件
> heatmap.pic1 <- read.csv("text.csv",header = T,row.names = 1) #文件一般需要 csv 格式,其中 header = T 代表首行为表头,row.names = 1 代表第一列是名字,不做读取。
举个例子,我的数据是这样的:
第四步:绘制热图
pheatmap(heatmap.pic1, #载入我们的数据
scale="column", #进行均一化处理, 可以是 "row","column" 以及 "none",如果不标志这条命令默认是 "none"
clustering_distance_rows = "correlation", #优化聚类线长度
treeheight_row=25, #按行聚类树高
treeheight_col=25, #按列聚类树高
cluster_cols=F, #是否按列聚类
cluster_rows=T, #是否按行聚类
display_numbers=F, #是否在每一格上显示数据
number_format="%.2f", #显示数据的格式,几位小数
fontsize_row=10, #行名称字体大小
fontsize_col=15, #列名称字体大小
main="heatmap", #标题名称
gaps_row = c(10, 15), #插入缝隙,不能聚类!
cutree_row = 3, #按聚类分割
show_colnames=TRUE, #是否显示列名
show_rownames=TRUE, #是否显示行名
color = colorRampPalette(c("green","black","red"),bias=1)(256), #定义颜色, 其中 “bias=1” 表示中间基准颜色在正中间,换成其他数字可以上下调,可以自己修改试试体会下。“(256)” 代表有 256 个颜色过渡,这个数字越大的话,颜色越平滑,也可以自己调节下
cellwidth = 50, #格子长度
cellheight= 14, #格子高度
border_color = "black", #格子框颜色
legend = FALSE, #是否显示图例
legend_breaks = -5:5, #图例范围
filename = "heatmap.pic1.pdf", #保存文件命名)
好啦,基本常用的功能已经总结给大家了,需要大家注意的是需要删掉后面的标注,选择自己需要的功能。以下两图为例:
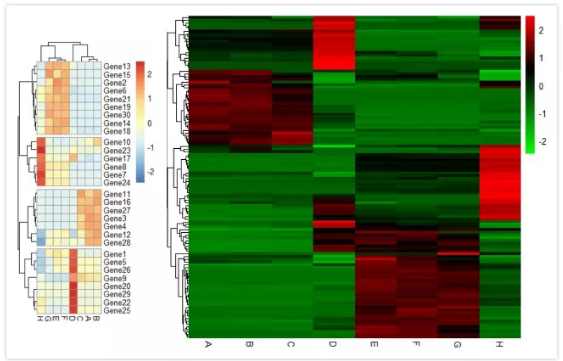
>pheatmap(heatmap.pic1,show_rownames=T,show_colnames=T,treeheight_row=20,treeheight_col=20,scale="row",cellwidth = 10,cellheight=10,cutree_row = 4) #显示行名列名,设置树高,,行归一化,格子长宽为 10,按聚类分为四类,其他方面默认处理。得到如左图效果图。
>pheatmap((heatmap.pic1,treeheight_row=20,,cluster_cols=FALSE,show_rownames=F,color = colorRampPalette(c("green","black","red"),bias=1)(256),scale="row") #行树高 20,列不聚类,不显示行名,三种颜色渐变,行归一化。得到如右图效果图。
(2)火山图
火山图经常用于展示差异表达的基因,常用于芯片、测序等组学检测技术的结果中,与热图可是一对好兄弟:
data =read.table("text.csv",header=T,row.names=1) #读取文件
p = ggplot(data,aes(log2FC,-undefinedlog10(symble))) + geom_point() #通过对样品取对数归一化处理样品,然后绘制火山图。
p + geom_point(aes(color =significant)) #增加点的颜色
p+geom_hline(yintercept=1.3)+geom_vline(xintercept=c(-1,1))
p+geom_hline(yintercept=1.3,linetype=4)+geom_vline(xintercept=c(-1,1),linetype=4) #增加阈值线,最终得到下图。
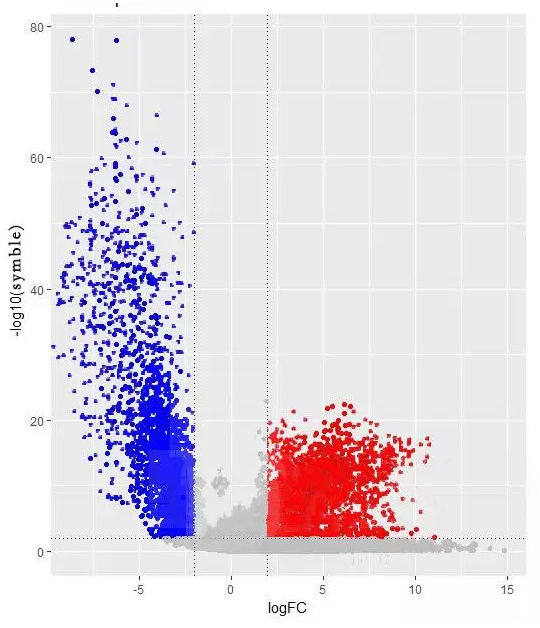
好的,本次的「套路」给大家讲完了,你是否学会应用在你的文章里了呢~
参考资料:
[1]R Graphics Cookbook by Winston Chang(O’Reolly).Copyright2013WinstonChang,978-1-449-361695-2.
[2]https://jingyan.baidu.com/article/647f0115d11aab7f2048a875.html
[3]https://jingyan.baidu.com/article/7f766daf87fedf4100e1d076.html
[4]Yang Q, Lin J, Miao L, et al. Highly sensitive sequencing reveals dynamic modifications and activities of small RNAs in mouse oocytes and early embryos[J]. Science Advances, 2016, 2(6):e1501482.




![[精选]SCI论文写作投稿资料包:100+资料& 投稿答疑30问](https://img1.dxycdn.com/p/s14/2023/1105/569/6102685706544601271.jpg!wh200)