手把手教你用 OpenBUGS 做统计
丁香园
OpenBUGS 软件是一款基于贝叶斯统计理论研发的统计软件,其允许用户给未知参数指定先验信息并使用 MCMC(Markov Chain Monte Carlo)方法来估计参数的后验分布,是贝叶斯统计推断的得力工具。
本文利用非条件 Logisitic 回归模型,研究少年儿童肥胖与胆固醇、甘油三酯、年龄和性别之间的关系,来介绍 OpenBUGS 软件的具体操作步骤。
数据来源于孙振球、徐勇勇主编的《医学统计学》第四版 P260 第二题。
用 ri 表示第 i 组少年儿童肥胖的阳性数,ni 表示第 i 组观察总例数,pi 表示第 i 组儿童肥胖的阳性率,则有 ri~Binomial(pi,ni)。
建立模型:
logit(pi)=β0+β1
其中 beta 用 β 表示;β0 为常数项,又称截距;βj(j=1,2,3,4) 为自变量 Xj 的偏回归系数;模型的参数 β0,β1,β2,β3 和 β4 已经给定了独立的「non-informative」先验分布。
第一步 | 模型的建立(New Model)
通过 OpenBUGS 软件进行 Doodle 建模,用来指定各参数的分布类型和逻辑关系,如图 1 所示:

图 1 Doodle 模型结构示意图
图 1 中每一个椭圆表示一个节点,矩形表示常数节点,单线箭头表示从父节点到随机型子节点,双线空心箭头表示从父节点到逻辑型子节点,边缘较粗的矩形为平板,其左下角的 「for(i IN 1:N)」表示 for 循环,实质是计算 N 个组的似然函数,从而获得整个数据的似然函数。
第二步 | 模型的检查(Check Model)
模型设定完成后,点击 Model 下拉菜单 Specification 中的 Check Model 按钮对模块进行检查,若检查无误,则软件窗口左下方会提示「Model is syntactically correct」,同时按钮 Load Data 和 Compile 被激活,提示可以加载数据并进行编译。
第三步 | 数据的加载(Load Data)和编译(Compile Model)
将鼠标移到数据指示语「List」并选中,点击 Load Data(加载数据)按钮,若左下方提示「Data loaded」,则点击 Compile 按钮进行编译,编译成功后,窗口底部左下方会提示「Model compiled」,随即 Load Inits 和 Gen Inits 按钮被激活 。
第四步 | 初始值的设定(Initial Values)
与加载数据类似,选中指示语 「List」,点击 Load Inits 按钮加载。
如果只产生一条链,此时窗口左下方出现「Model is initialized」,Gen Inits 按钮变灰,提示初始值设置完成。
如果产生 2 条或 2 条以上的链,此时窗口左下方提示「Initial values loaded but chain contains uninitialized variables」,继续点击 Gen Load 按钮,提示「Initial values generated, Model is initialized 」,初始值设定完成。
第五步 | 模型的退火(Burn In)
点击 Inference 下拉菜单中的 Samples 按钮,在弹出的 「Sample Monitor Tool」 对话框中的 Beg 处输入相应的数字,如输入 1 000 则表示抛去前 1 000 次抽样以消除初始值对抽样的影响,实现对模型的退火,从 1 001 次开始抽样。
第六步 | 变量的监控(Monitor Nodes)
通过点击 Inference 下拉菜单中的 Samples,在弹出的对话框 Node 处,添加自己想要观察的变量名(本例主要观察的变量为 β0,β1,β2,β3,β4),逐一按 Set 键确定,同时可以在 Percentiles 下方的列表中选择给出的置信区间,默认为 95%(val2.5pc,val97.5pc)置信区间。
第七步 | 模型的迭代(Updates)
通过点击 Model 下拉菜单中的 Updates 按钮对模型进行迭代运算,迭代的次数和步长可以自行设置。
第八步 | 结果的输出(Output)
通过 Inference 下拉菜单中 Samples 选项,在打开的「Sample Monitor Tool」对话框中的 Node 处输入前面指定的观察参数,也可以直接输入「」(「」代表所有指定的参数),就可以获得各参数后验分布统计量,如图 2-7 所示。
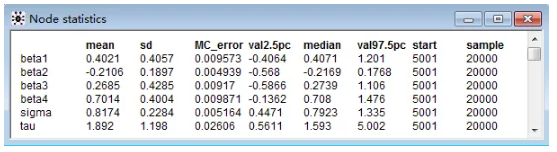
图 2 各参数后验分布统计量
其中:
MC_error 表示蒙特卡罗模拟的误差,用来度量由模拟引起的参数均值的方差;
val2.5pc 和 val97.5pc 分别表示中位数的 95% 置信区间的下限和上限;Median 表示中位数,通常比 Mean 更稳定;
Start 表示 Gibbs 抽样得起始点,Sample 表示总共抽取的样本数。
图 3 核密度图
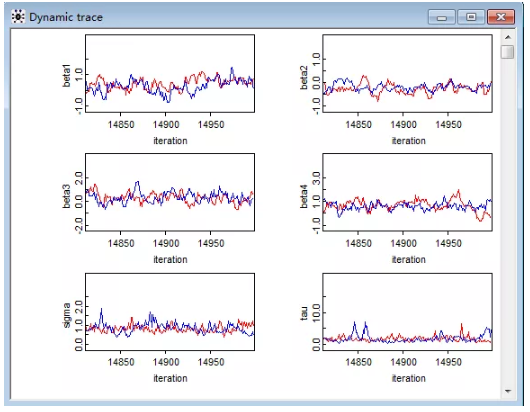
图 4 迭代轨迹图
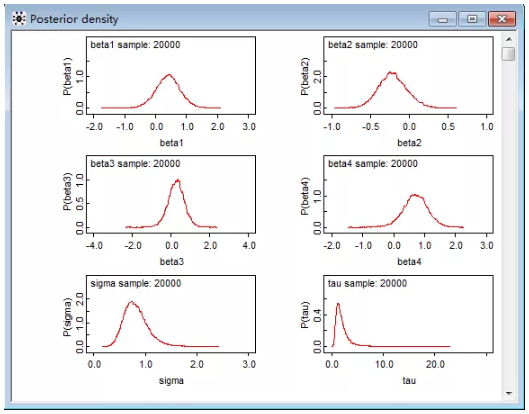
图 5 分位数图
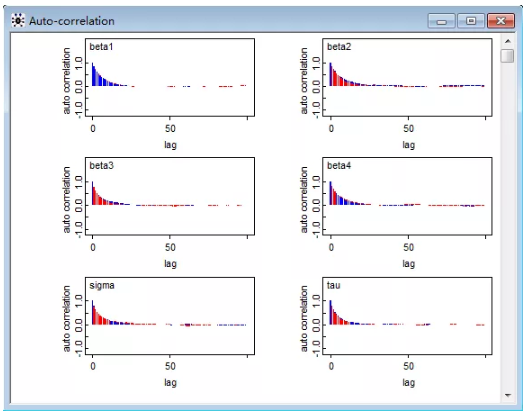
图 6 自相关函数图
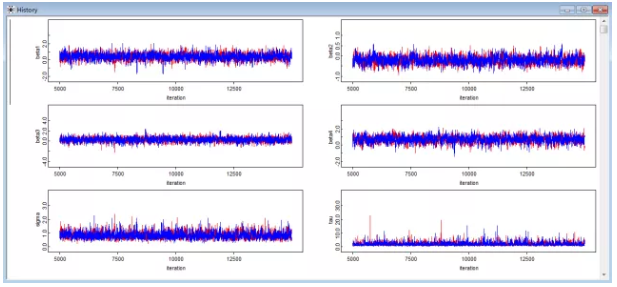
图 7 迭代历史图
第九步 | 收敛性的判别
模型的收敛性可以通过观察遍历均值进行判断,在得到的链中每隔一段距离计算所观察参数的遍历均值,当这样算的的均值稳定后,可认为模型收敛。
也可以通过迭代轨迹图和迭代历史图来进行判断,当迭代轨迹和历史迭代趋于稳定,可以认为模型收敛。
最后得到的回归方程为:Logit(pi)=-2.14-0.52X1-0.23X2+0.26X3+0.79X4。
本文仅仅对 OpenBUGS 软件做了一个简单的介绍,通过实例应用,使读者对该软件有一个初步的了解,并能掌握 OpenBUGS 软件的基本操作。