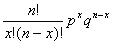材料与仪器
步骤
此节主要分为两个子节。在 3.1 节中,我们提出与库的设计与表征相关的问题。在 3.2 节中,我们分析评价库的质量或者库的筛选结果的显著性。在前两节中,我 们给出了公式以及提供了数值范例,用示例来加以说明而没有给出详细的理论解释。完整的理论说明可以在注释(见 8.4 节)中找到。
3.1 库表征
我们设计一个包含 n 个可能的不同的理论变量库。我们从这个理论库中随机取样 m 次;形成一个 m 个变量的样本集。我们提出如下问题。
A. 在选择的 m 个变量中我们期待多少个理论变量(全部为 n 个)不会出现?
B. 在选择的 m 个变量中至少一个理论变量(全部为 n 个)没有被取样的概率是多少?最多一定量的理论变量(全部为 n 个)没有被取样的概率是多少?
C. 我们期待一个特定变量 i 多少次出现在样本中?更通俗地说,i 出现 r 次的概率是多少?
这些问题作为一组提出,是因为如 3.1.1 节和 3.1.2 节中所述,上述问题的解决是基于同样的理论。我们用尺表示当我们随机地从理论库中取样一次变量 i 出现任意次的概率。
我们分成两种不同情形,在下面的小节中不同处理:
( 1 ) 在 3.1.1 节中,等概率结果,即 n 个变量被取样的概率是相同的。这里 Pi =1/n,这个例子被作为一般化处理。
( 2 ) 在 3.1.2 节中,这里结果的出现是非等概率型的,即一些变量比其他一些有更好的概率被取样。根据定义,很难把这种情形进行一般化处理,因为对于上述问 题 A、B 和 C,答案取决于概率本身。作为示例,我们详细处理一种非等概率的情形。
如果一个给定序列出现的频率或者我们感兴趣的被编码的特性都没有任何偏差,则称为等概率情形。在这种情形的库选择中,如果我们感兴趣的性质是独立于其他参数的,或者对其他参数的影响可以忽略,我们考虑其为等概率的。如果考虑密码子具有偏好性或简并性,或者结果会影响到整个系统,则为非等概率情形。一个结果影响 整个系统的例子如下:当在体内筛选酶 X 的高催化活性时,增加的产物会对整个系统有毒性,产生对检测酶催化活性的不良反应。这样的参数一般来说过去复杂而不用系统地说明。然而我们可以考虑利用偏好性密码子,其中氨基酸的出现是非等概率事件,其他参数尽管也是非等概率的,但是可以被量化。
3.1.1 等概率情形
这是最简单的情形,其中所有结果都可以被考虑成等概率事件:对库中的成员进行取样后,所有 n 个变量都有同样的机会被选中,即 Pi =1/n。

注意,缺失变量数目的期望值不必是整数;这里缺失变量数目的期望值为 45~46 个(整体理论变量数目为 1 X 106 个)。
如果我们从 n = 1 X 106 个理论变量库中取样 m = 2 X 107 次,则 λ = 0.00206。这样,缺失变量的期望值为 0 或 1 个,且更加接近于 0。事实上,在这个例子中,0 或 1 个变量缺失的概率是仅有的非小概率事件,0 缺失更加可能(> 99%,见 3.1.1 问题 B 中的计算)。
我们可以得出结论:取样大小为理论库的 20 倍时(m = 20 n),可以导致原则上对理论库的完全取样,如图 8.5 所示。取样 10 倍过量可以导致一小部分组分没有被取样 ( 当理论库中少于 104 个变量时,此组分趋向于 0,见表 8.2 );对于很多的实验目的来说,知道还有一小部分没有被取样已经达到要求。


请注意表 8.2 给出一些违反直觉的结果:如果取样大小 m 等于库的大小 n,我们可以期待平均大概 37% 的理论变量将不被取样;甚至当 m=2n 时,理论变量不被取样的平均概率是 13.5%,远小于应该被完全取样的结果。

对于我们的主要例子(n= 1 X 106;m= 2 X 107) ,从 n 个理论变量中选取的 m 次中少于 50 个没有被取样的概率可以由加和每一个 0,1,2,…,直到 49 个没有被取样的概率计算得出,大约是 78%,即

与此类似,少于 60 个没有被取样的概率大约是 98%。为了简化计算,可以利用 Excel 计算单(见 8.2 节及图 8.1)。

即小于 1% 的机会。某个变量出现 3 次的结果会提示系统中有偏差吗(如由于选择压力造成的)?关于这个问题的讨论见 8.3.2 节。

最后,某变量出现 10 次或以下的概率可以由相加出现 10 次,9 次等的概率直到出现 0 次的概率算出,可以手算也可以利用 Excel 工作单(见 8.2 及图 8.1)。我们看到在这个例子中出现 10 次或更少的概率大约是 58.3%。
3.1.2 非等同概率的一个例子
我们给出出现非等同概率事件的一个例子,即 n 个变量中的一些变量会比平均情况更多或更少的机会出现。如 3.1 节开头所述,很难得出非等同概率事件的普遍规律,因为答案取决于具体概率是什么。我们这里提供的例子中给出一些简明的计算,同时也提示了可能遇到的困难。
在没有选择压力时,非等同概率事件可以在有偏好的 DNA 库中出现,这种库偏好性可以是设计的也可以是意外产生的。例如,在寡核苷酸引物合成过程中出现的意外偏差。这样的偏差可以在随机取样 DNA 库测序后发现。如果我们用编码蛋白质序列而不是 DNA 序列来定义理论库,那么非等同概率依然会出现。例如;当 “ NNN ”型密码子编码时,将会出现 6 个编码亮氨酸的每一个密码子出现的概率与唯一编码甲硫氨酸密码子出现的概率相等,因此在同一位点得到含有亮氨酸的蛋白质的概率将是得到含有甲硫氨酸的蛋白质概率的 6 倍。
在选择压力存在时,实验开始时一般来说不可能精确数值定义出某些突变相关的选择优势或者劣势。事实上,在有选择压力时最好反过来问问题:与其问给出特定的序列偏好,某种变种以何种概率出现,不如问在选择出的子集中我们能够观察到的序列的实验频率。我们能够确定这样的频率是否为期待的如 3.1.13 中的问题 C),或者是否出现了偏差。
1 ) 我们这个非等同概率例子的特征
我们考虑在十肽中取样。如果 10 个氨基酸在十肽中是随机分布的(NNN) ,会有 2110=1.67X1013 种不同的理论变种(我们对待终止子与其他氨基酸相同)。因为密码子的简并性每种氨基酸以非等同概率被选择;尽管如此,能够发生的不同概率为下列 5 种:
其中 Met 和 Trp 分别被 64 个密码子中的一个编码;Phe、Tyr、His、Gln、Asn、Lys、Asp、Glu 和 Cys 分别被 64 个密码子中的两个编码等。因此,上述 5 种概率所对应的氨基酸种类,分别为 2、9、2、5 以及 3 种氨基酸或终止密码子。
2 ) 问题 A
在 n 个理论变种中选出 m 个,我们可以预计多少个不出现?
要解决这个问题,要素是考虑密码子的简并性。我们假定每个特异的十肽无论其氨基酸排列顺序如何,都具有与其他相同氨基酸组成(因此具有同样的简并性)的十肽相同的出现概率。则问题 A 的答案是参数 λ ( 见注 7 ),计算式为

上述加和号是对所有 5 个数(n1、n2、n3、n4、n5)组成的数组的不同排序求和,相应于给定密码子简并性的 5 种概率。每个取自集合 { 0,1,2,…,10 } 的 “ 5 数组” 代表十肽中 5 种不同简并度的氨基酸各占多少。因为我们只考虑 10 种氨基酸。例如,(n1、n2、n3、n4、n5)= ( 8,0,0,1,1 ) 意味着一个十肽中的 8 个位置是由非简并氨基酸(1/64 ) 编码,不包含简并度为 2/64 和 3/64 的氨基酸,10 个位置中简并度为 4/64 和 6/64 的氨基酸各有一个。
P(n1、n2、n3、n4、n5)可以计算为

这个 P(n1、n2、n3、n4、n5)是我们在 3.1 节开头简要介绍的 Pi 的一个新名字,意味着当我们从理论库中随机取样一次,特定蛋白变种出现任意次的概率。
不幸的是,对于参数 λ 似乎不存在更简单的表述;要计算 A 的求和必如利用计算机编程。
例如,我们要从理论库 n=2110 ( 即约 1.67 X 1013;见图 8.2 ) 中随机取出 m = 1014 个十肽。
对于这组 m 和 n 的答案是 λ = 5.04 X 1012,因此我们预计从 1.67 X 1013 的理论库中随机取样有 5.04 X 1012 个不出现,大概的比率是 30%。
3 ) 问题 B
样本中至少有一种多肽变种不被产生出来的概率是多少?最多 50 或 60 种多肽变种没有被取样的概率是多少?
这样的概率可以由 3.1.1 节中有关等概率事件方程(8.2 ) 得到;但是参数 λ 的值必须由方程(8.6 ) 计算。因此,至少一种多肽不被取样的概率可以近似为(见注 5)。
计算 “至少” 或者 “最多” 特定数目多肽不被取样的概率可由 8.3.1.12 ) 的方法得出,这里不再赘述。 .
例如,我们再次从理论库 n = 2110≈1.67 X 1013 中随机取出 m=1014 个十肽;并且在 8.3.1.1 的子节 2 ) 中求得 λ= 5.04 X 1012。显然,对于 λ = 5.04X 1012 的预计缺失变种,直觉认为至少缺失一个的概率应该是很高的。利用式(8.8 ),我们确实可以求出此概率是 100%。换句话说,可产生出所有蛋白质变种的概率是 0%。
事实上,在所有多肽变种中最多 50 或 60 种不被产生的概率也是 0%。对于这样的高 λ 值(5.04X1012 ),这样的结果并不奇怪。
4 ) 问题 C
在一个样本中,我们可以预计含有 7 个概率为 3/64 的密码子和 3 个概率为 4/64 的密码子的十肽会出现多少次?这样的十肽出现 10 次的概率是多少?3 次呢?出现 10 次及 10 次以下的概率呢?
因为对于所有的在这个问题中所定义构成的肽来说,结果将会是一样的,所以我们没有必要去关心确切的序列( 比如氨基酸的次序和名称 )。这些问题的答案只是在 8.3.1.1 的 3 ) 中给出的问题中有微小的差别。因为对任意的十肽进行抽样后一个十肽出现的概率为 P [ 见 8.3.1.1 的 2 ) ],这样我们所预计的十肽出现的次数就是 mp,这里 m 是抽样的次数。考虑到一些十肽会被抽样超过一次,这样概率将会随着抽样次数而增加,所预计的十肽出现一定次数的概率近似服从参数为 λ=mp 的泊松分布(参见注 3 和注 8)。
也就是说,我们可以期望在样本中找到 λ = mp = 1014 X ( 1.21 X 10-13 ) ≈12.14 次这个十肽。出现十次的概率为

同样的,特定的十肽出现 3 次的概率近似为 0.16%,远远小于出现 10 次的机会 ( 10% ) 。把小于 10 次的概率全部加起来,我们得到出现小于或等于 10 次的概率近似为 33% ( 图 8.3)。
3.2 实验偏差的检验
这一节的基本问题可以表述为具有两个或两个以上可能观测值的试验进行了多次,也就是,多次取样的问题。每个观测值的理论概率(预期的)是已知的,而观测值的试验概率可以通过观察得到。理论概率和试验概率间的差别是否是显示实验有显著性偏差(biased) 的信号?
如节 8.1 中被提及的,在选择之前或者之后,这样的分析可以被常规地应用到 DNA 测序结果中测试偏差。应用下面提到的 X2 检验可以让试验者确定观察到的偏差是显著的还是不显著的。
现在由以下记号来提出问题:一个试验在理论上得到 k 个观测值 A1,A2,…,Ak 的概率分别为 p1,p2,pk。例如,对一个蛋白质库取样可以得到 k = 2 个结果:有功能或非功能的。这个试验被做了 n 次(也就是,n 个蛋白质被随机地抽样),则试验结果在每个观测值中出现的次数分别是 Y1,Y2,…, Yk 次。
X2 检验
X2 检验中的统计量为

我们要检验的假设,被称作 “零假设”,是试验以合适方式进行时的平均值,也就是说,以这一方式所得各个观测值的概率符合它们的理论概率。一个大的 q 值表明真实的试验结果与期望的结果之间存在显著的差异,而与零假设矛盾。
把统计量 q 与参数为 k-1 在任意选择的显著性水平 α 下得到的值 Xα2 比较。参数 α 的值由使用者指定(关于显著性水平见注 9) 。检验如下:
当 q<Xα2(k-1) 时,接受原假设;没有充分的理由认为存在偏差。
当 q>Xα2(k-1) 时,拒绝原假设;有充分的理由认为存在偏差。
X2 分布的临界值可以在大部分的统计学课本和很多软件,如 Excel 中查到。

原假设(试验以无偏好的正确方式进行)被接受( 图 8. 4 ) 。图 8.7 描述了该假设具有应该被接受(17~33 个观测值的特征)还是被拒绝(所有其他结果)的特征的观测值个数。


表明统计量 q,以及对期望结果的不符合性不足够大,因此我们可以得出结论认为在这个学生的操作步骤中存在瑕疵;而原假设没法被拒绝。然而,如果我们取 α=10%,则 X0.102 ( 2 ) = 4.605,检验变成了:q = 5.6 > 4.605 = X0.102( 2 ) 这样,我们能够拒绝原假设,认为现在的试验是所期望的。
3.1 库表征
我们设计一个包含 n 个可能的不同的理论变量库。我们从这个理论库中随机取样 m 次;形成一个 m 个变量的样本集。我们提出如下问题。
A. 在选择的 m 个变量中我们期待多少个理论变量(全部为 n 个)不会出现?
B. 在选择的 m 个变量中至少一个理论变量(全部为 n 个)没有被取样的概率是多少?最多一定量的理论变量(全部为 n 个)没有被取样的概率是多少?
C. 我们期待一个特定变量 i 多少次出现在样本中?更通俗地说,i 出现 r 次的概率是多少?
这些问题作为一组提出,是因为如 3.1.1 节和 3.1.2 节中所述,上述问题的解决是基于同样的理论。我们用尺表示当我们随机地从理论库中取样一次变量 i 出现任意次的概率。
我们分成两种不同情形,在下面的小节中不同处理:
( 1 ) 在 3.1.1 节中,等概率结果,即 n 个变量被取样的概率是相同的。这里 Pi =1/n,这个例子被作为一般化处理。
( 2 ) 在 3.1.2 节中,这里结果的出现是非等概率型的,即一些变量比其他一些有更好的概率被取样。根据定义,很难把这种情形进行一般化处理,因为对于上述问 题 A、B 和 C,答案取决于概率本身。作为示例,我们详细处理一种非等概率的情形。
如果一个给定序列出现的频率或者我们感兴趣的被编码的特性都没有任何偏差,则称为等概率情形。在这种情形的库选择中,如果我们感兴趣的性质是独立于其他参数的,或者对其他参数的影响可以忽略,我们考虑其为等概率的。如果考虑密码子具有偏好性或简并性,或者结果会影响到整个系统,则为非等概率情形。一个结果影响 整个系统的例子如下:当在体内筛选酶 X 的高催化活性时,增加的产物会对整个系统有毒性,产生对检测酶催化活性的不良反应。这样的参数一般来说过去复杂而不用系统地说明。然而我们可以考虑利用偏好性密码子,其中氨基酸的出现是非等概率事件,其他参数尽管也是非等概率的,但是可以被量化。
3.1.1 等概率情形
这是最简单的情形,其中所有结果都可以被考虑成等概率事件:对库中的成员进行取样后,所有 n 个变量都有同样的机会被选中,即 Pi =1/n。
注意,缺失变量数目的期望值不必是整数;这里缺失变量数目的期望值为 45~46 个(整体理论变量数目为 1 X 106 个)。
如果我们从 n = 1 X 106 个理论变量库中取样 m = 2 X 107 次,则 λ = 0.00206。这样,缺失变量的期望值为 0 或 1 个,且更加接近于 0。事实上,在这个例子中,0 或 1 个变量缺失的概率是仅有的非小概率事件,0 缺失更加可能(> 99%,见 3.1.1 问题 B 中的计算)。
我们可以得出结论:取样大小为理论库的 20 倍时(m = 20 n),可以导致原则上对理论库的完全取样,如图 8.5 所示。取样 10 倍过量可以导致一小部分组分没有被取样 ( 当理论库中少于 104 个变量时,此组分趋向于 0,见表 8.2 );对于很多的实验目的来说,知道还有一小部分没有被取样已经达到要求。
请注意表 8.2 给出一些违反直觉的结果:如果取样大小 m 等于库的大小 n,我们可以期待平均大概 37% 的理论变量将不被取样;甚至当 m=2n 时,理论变量不被取样的平均概率是 13.5%,远小于应该被完全取样的结果。
对于我们的主要例子(n= 1 X 106;m= 2 X 107) ,从 n 个理论变量中选取的 m 次中少于 50 个没有被取样的概率可以由加和每一个 0,1,2,…,直到 49 个没有被取样的概率计算得出,大约是 78%,即
与此类似,少于 60 个没有被取样的概率大约是 98%。为了简化计算,可以利用 Excel 计算单(见 8.2 节及图 8.1)。
即小于 1% 的机会。某个变量出现 3 次的结果会提示系统中有偏差吗(如由于选择压力造成的)?关于这个问题的讨论见 8.3.2 节。
最后,某变量出现 10 次或以下的概率可以由相加出现 10 次,9 次等的概率直到出现 0 次的概率算出,可以手算也可以利用 Excel 工作单(见 8.2 及图 8.1)。我们看到在这个例子中出现 10 次或更少的概率大约是 58.3%。
3.1.2 非等同概率的一个例子
我们给出出现非等同概率事件的一个例子,即 n 个变量中的一些变量会比平均情况更多或更少的机会出现。如 3.1 节开头所述,很难得出非等同概率事件的普遍规律,因为答案取决于具体概率是什么。我们这里提供的例子中给出一些简明的计算,同时也提示了可能遇到的困难。
在没有选择压力时,非等同概率事件可以在有偏好的 DNA 库中出现,这种库偏好性可以是设计的也可以是意外产生的。例如,在寡核苷酸引物合成过程中出现的意外偏差。这样的偏差可以在随机取样 DNA 库测序后发现。如果我们用编码蛋白质序列而不是 DNA 序列来定义理论库,那么非等同概率依然会出现。例如;当 “ NNN ”型密码子编码时,将会出现 6 个编码亮氨酸的每一个密码子出现的概率与唯一编码甲硫氨酸密码子出现的概率相等,因此在同一位点得到含有亮氨酸的蛋白质的概率将是得到含有甲硫氨酸的蛋白质概率的 6 倍。
在选择压力存在时,实验开始时一般来说不可能精确数值定义出某些突变相关的选择优势或者劣势。事实上,在有选择压力时最好反过来问问题:与其问给出特定的序列偏好,某种变种以何种概率出现,不如问在选择出的子集中我们能够观察到的序列的实验频率。我们能够确定这样的频率是否为期待的如 3.1.13 中的问题 C),或者是否出现了偏差。
1 ) 我们这个非等同概率例子的特征
我们考虑在十肽中取样。如果 10 个氨基酸在十肽中是随机分布的(NNN) ,会有 2110=1.67X1013 种不同的理论变种(我们对待终止子与其他氨基酸相同)。因为密码子的简并性每种氨基酸以非等同概率被选择;尽管如此,能够发生的不同概率为下列 5 种:
其中 Met 和 Trp 分别被 64 个密码子中的一个编码;Phe、Tyr、His、Gln、Asn、Lys、Asp、Glu 和 Cys 分别被 64 个密码子中的两个编码等。因此,上述 5 种概率所对应的氨基酸种类,分别为 2、9、2、5 以及 3 种氨基酸或终止密码子。
2 ) 问题 A
在 n 个理论变种中选出 m 个,我们可以预计多少个不出现?
要解决这个问题,要素是考虑密码子的简并性。我们假定每个特异的十肽无论其氨基酸排列顺序如何,都具有与其他相同氨基酸组成(因此具有同样的简并性)的十肽相同的出现概率。则问题 A 的答案是参数 λ ( 见注 7 ),计算式为
上述加和号是对所有 5 个数(n1、n2、n3、n4、n5)组成的数组的不同排序求和,相应于给定密码子简并性的 5 种概率。每个取自集合 { 0,1,2,…,10 } 的 “ 5 数组” 代表十肽中 5 种不同简并度的氨基酸各占多少。因为我们只考虑 10 种氨基酸。例如,(n1、n2、n3、n4、n5)= ( 8,0,0,1,1 ) 意味着一个十肽中的 8 个位置是由非简并氨基酸(1/64 ) 编码,不包含简并度为 2/64 和 3/64 的氨基酸,10 个位置中简并度为 4/64 和 6/64 的氨基酸各有一个。
P(n1、n2、n3、n4、n5)可以计算为
这个 P(n1、n2、n3、n4、n5)是我们在 3.1 节开头简要介绍的 Pi 的一个新名字,意味着当我们从理论库中随机取样一次,特定蛋白变种出现任意次的概率。
不幸的是,对于参数 λ 似乎不存在更简单的表述;要计算 A 的求和必如利用计算机编程。
例如,我们要从理论库 n=2110 ( 即约 1.67 X 1013;见图 8.2 ) 中随机取出 m = 1014 个十肽。
对于这组 m 和 n 的答案是 λ = 5.04 X 1012,因此我们预计从 1.67 X 1013 的理论库中随机取样有 5.04 X 1012 个不出现,大概的比率是 30%。
3 ) 问题 B
样本中至少有一种多肽变种不被产生出来的概率是多少?最多 50 或 60 种多肽变种没有被取样的概率是多少?
这样的概率可以由 3.1.1 节中有关等概率事件方程(8.2 ) 得到;但是参数 λ 的值必须由方程(8.6 ) 计算。因此,至少一种多肽不被取样的概率可以近似为(见注 5)。
计算 “至少” 或者 “最多” 特定数目多肽不被取样的概率可由 8.3.1.12 ) 的方法得出,这里不再赘述。 .
例如,我们再次从理论库 n = 2110≈1.67 X 1013 中随机取出 m=1014 个十肽;并且在 8.3.1.1 的子节 2 ) 中求得 λ= 5.04 X 1012。显然,对于 λ = 5.04X 1012 的预计缺失变种,直觉认为至少缺失一个的概率应该是很高的。利用式(8.8 ),我们确实可以求出此概率是 100%。换句话说,可产生出所有蛋白质变种的概率是 0%。
事实上,在所有多肽变种中最多 50 或 60 种不被产生的概率也是 0%。对于这样的高 λ 值(5.04X1012 ),这样的结果并不奇怪。
4 ) 问题 C
在一个样本中,我们可以预计含有 7 个概率为 3/64 的密码子和 3 个概率为 4/64 的密码子的十肽会出现多少次?这样的十肽出现 10 次的概率是多少?3 次呢?出现 10 次及 10 次以下的概率呢?
因为对于所有的在这个问题中所定义构成的肽来说,结果将会是一样的,所以我们没有必要去关心确切的序列( 比如氨基酸的次序和名称 )。这些问题的答案只是在 8.3.1.1 的 3 ) 中给出的问题中有微小的差别。因为对任意的十肽进行抽样后一个十肽出现的概率为 P [ 见 8.3.1.1 的 2 ) ],这样我们所预计的十肽出现的次数就是 mp,这里 m 是抽样的次数。考虑到一些十肽会被抽样超过一次,这样概率将会随着抽样次数而增加,所预计的十肽出现一定次数的概率近似服从参数为 λ=mp 的泊松分布(参见注 3 和注 8)。
也就是说,我们可以期望在样本中找到 λ = mp = 1014 X ( 1.21 X 10-13 ) ≈12.14 次这个十肽。出现十次的概率为
同样的,特定的十肽出现 3 次的概率近似为 0.16%,远远小于出现 10 次的机会 ( 10% ) 。把小于 10 次的概率全部加起来,我们得到出现小于或等于 10 次的概率近似为 33% ( 图 8.3)。
3.2 实验偏差的检验
这一节的基本问题可以表述为具有两个或两个以上可能观测值的试验进行了多次,也就是,多次取样的问题。每个观测值的理论概率(预期的)是已知的,而观测值的试验概率可以通过观察得到。理论概率和试验概率间的差别是否是显示实验有显著性偏差(biased) 的信号?
如节 8.1 中被提及的,在选择之前或者之后,这样的分析可以被常规地应用到 DNA 测序结果中测试偏差。应用下面提到的 X2 检验可以让试验者确定观察到的偏差是显著的还是不显著的。
现在由以下记号来提出问题:一个试验在理论上得到 k 个观测值 A1,A2,…,Ak 的概率分别为 p1,p2,pk。例如,对一个蛋白质库取样可以得到 k = 2 个结果:有功能或非功能的。这个试验被做了 n 次(也就是,n 个蛋白质被随机地抽样),则试验结果在每个观测值中出现的次数分别是 Y1,Y2,…, Yk 次。
X2 检验
X2 检验中的统计量为
我们要检验的假设,被称作 “零假设”,是试验以合适方式进行时的平均值,也就是说,以这一方式所得各个观测值的概率符合它们的理论概率。一个大的 q 值表明真实的试验结果与期望的结果之间存在显著的差异,而与零假设矛盾。
把统计量 q 与参数为 k-1 在任意选择的显著性水平 α 下得到的值 Xα2 比较。参数 α 的值由使用者指定(关于显著性水平见注 9) 。检验如下:
当 q<Xα2(k-1) 时,接受原假设;没有充分的理由认为存在偏差。
当 q>Xα2(k-1) 时,拒绝原假设;有充分的理由认为存在偏差。
X2 分布的临界值可以在大部分的统计学课本和很多软件,如 Excel 中查到。
原假设(试验以无偏好的正确方式进行)被接受( 图 8. 4 ) 。图 8.7 描述了该假设具有应该被接受(17~33 个观测值的特征)还是被拒绝(所有其他结果)的特征的观测值个数。
表明统计量 q,以及对期望结果的不符合性不足够大,因此我们可以得出结论认为在这个学生的操作步骤中存在瑕疵;而原假设没法被拒绝。然而,如果我们取 α=10%,则 X0.102 ( 2 ) = 4.605,检验变成了:q = 5.6 > 4.605 = X0.102( 2 ) 这样,我们能够拒绝原假设,认为现在的试验是所期望的。
来源:丁香实验