代谢物质谱鉴定金标准
鹿明生物
1.代谢组学数据存在的弊端
代谢组学相较于系统生物学的其他组学来说,拥有海量的数据(尤其是非靶向代谢组学数据),通常来说,代谢组学数据的特点有:
a.高噪声:生物体内含有大量维持机体生理作用和功能的内源性小分子,具有特定研究意义的生物标志物以及功能代谢物只是其中很少的一部分。绝大部分的代谢物和研究目的无关,这就造成了在整体代谢物背景下,少部分的功能代谢物受到绝大部分无用代谢物的噪声干扰会相对严重;
b.高维度(相对小样本):通常来说,非靶向代谢组检测到的代谢物的数量远大于样本个数,因此处理代谢组的数据不能选择使用传统的统计学方法;
c.鉴定难度大:多方面的因素导致代谢组的数据的鉴定和定性难度较大,比如同分异构体、理化性质相近的代谢物、液相体系、代谢物质谱结构解析的困难等等。
d.高度不规则:代谢组数据分布很不规则,有可能数据中会出现很多 0 值,这需要采用更加复杂合理的统计分析策略来揭示隐藏其中的复杂数据关系。
一份数据,要承受多少次的鉴定筛选,才能熬过 reviewer 的火眼;
你是否曾经历过 reviewer 对于数据鉴定的质疑,比如:
1.It seems there are many wrong metabolite identifications;
2.How the authors identify the isomers because are no standards described in the manuscrip;
3.Please add information of MS2 and mass error in Table;
……
2.避免审稿小技巧—数据鉴定的标准化
防患于未然,把数据鉴定标准化、明确化和数据化显得尤为重要,在文章中适当呈现,是避免一系列审稿意见的小小技巧。
接下来要给大家介绍的就是 2020 年 Cell 杂志上发表的两篇有关组学系列文章中对于代谢物鉴定的经典描述:
文献案例_代谢物数据鉴定标准
随着代谢组的不断发展,目前对于代谢组学鉴定的要求越来越高,西湖大学郭天南研究员团队 2020 年 7 月发表在 Cell 杂志上的“Proteomic and Metabolomic Characterization of COVID-19 Patient Sera”【1】中就有关于代谢物鉴定提到三个明确的条件:
a.狭窄的窗口保留指数(RI)
b.变化小于10 ppm 的质量精度(MS1)
c.高正反双向的 MS/MS 得分(MS2)

图 | 该文章中关于 3 个鉴定条件的描述
而在前一个月,同样是 Cell 主刊在线发布的一篇关于孕妇代谢动力学与妊娠年龄及分娩时间的预测文章中同样提到关于代谢物鉴定的过程和标准,
主要基于以下几个方面:
a.变化小于 5 ppm 的质量精度(MS1)
b.保留时间 RT 在 30s 的波动范围内
c.MS/MS 匹配

总结来说,鉴定准确度排序:standards>MS/MS>MetDNA.
基于上述两篇文章来看:以保留时间 RT、一级质谱 MS1、二级质谱 MS2 三个维度的鉴定是目前代谢组学代谢物鉴定中较为通用可靠的方式。因此,基于该三个维度建立开发本地数据库是目前较为迫切的需求(鹿明生物目前已自建了 LUG 数据库和 EMDB 数据库),而稳定一致的质谱平台在一定程度上也有利于本地数据库的实现。
3.标准化的三维度—代谢物鉴定
首先来个小科普... ...
什么叫可信代谢物?简单来讲,通过多维度的匹配后能相对较为准确地得到注释的代谢物,这些代谢物就可以成为可信代谢物。
那么多维度是指的哪些维度呢?一般情况下,基于液相色谱质谱的代谢组学目前鉴定和定性的维度有三个:RT(保留时间);MS1(一级质谱);MS2(二级质谱);接下来给大家介绍一下三个维度的相关内容:
RT:保留时间
RT:保留时间:是指从进样开始到某一组分浓度达到最大值所需要的时间,简单点说,就是该物质的实际出峰时间。理论上来说,一台相对稳定的色谱质谱联用仪,在色谱柱以及流动相等体系一致的情况下,单个代谢物的保留时间应该稳定在某个值的较窄范围内。
示例:下图展示了鹿明生物代谢组平台基于 3 个不同质谱平台多套色谱及色谱柱体系检测相同的内标物(2-氯-苯丙氨酸:理论精确分子量,199.040009)的 5 种保留时间出峰情况:
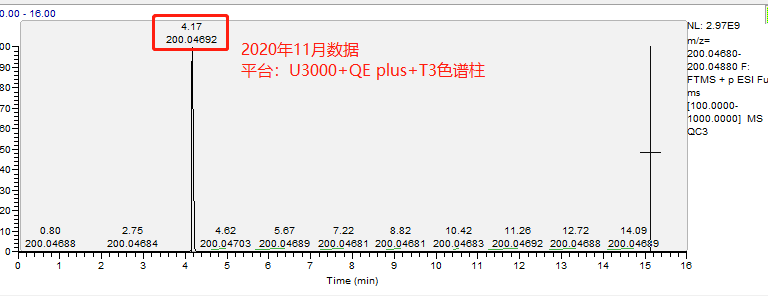
图 1 | 平台 A 11 月数据,Waters T3 色谱柱检测
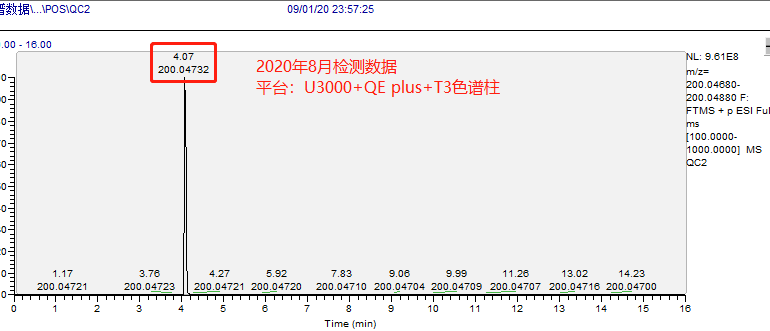
图 2 | 平台 A 8 月数据,Waters T3 色谱柱检测
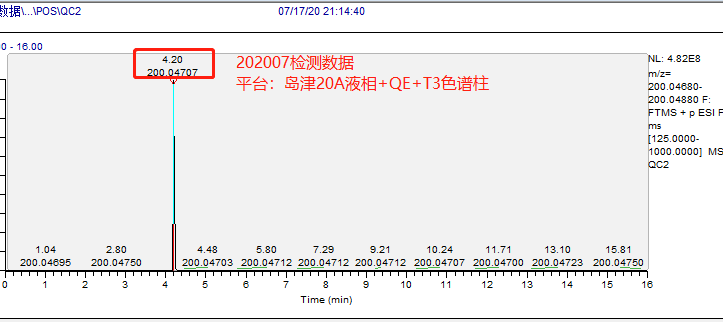
图 3 | 平台 B 7 月数据,Waters T3 色谱柱检测
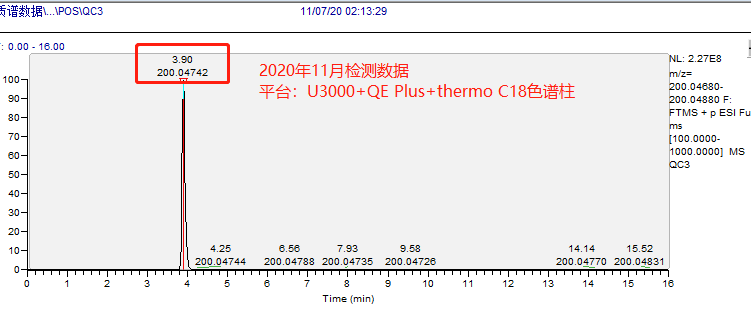
图 4 | 平台 C 11 月数据,Thermo C18 色谱柱检测
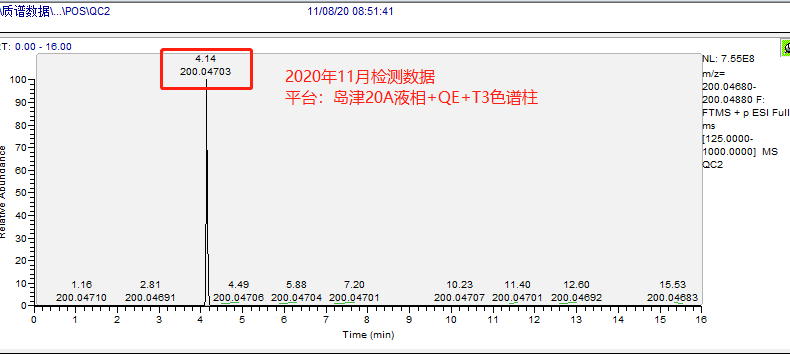
图 5 | 平台 B 11 月数据,Waters T3 色谱柱检测
对比结果如下表所示:
表 1 | 基于保留时间维度的不同平台数据对比情况

因此,基于保留时间建数据库的可能性理论上是可行的,这也是未来自建数据库发展的方向。
MS1:一级质谱:
MS1:一级质谱:一般指的是检测到的带电离子的质荷比。在代谢组学的质谱检测过程中,一级质谱和代谢物的分子离子峰有着密切的关联,通常我们称此联系为离子加和模式,理论分子量通过某种离子加和形式得到的就是我们常说的一级质谱(MS1)。在代谢组数据中,通常用来评价代谢物鉴定准确度的一级质谱信息为质荷比的质量精度,即实际检测的化合物的MS1 和理论上的质量数进行质量精度的计算。所以一般来说,控制一级质谱的质量精度就能控制代谢物鉴定的准确度,质量精度越小,误差越小。
同样,我们使用上述内标来计算该内标在质谱检测过程中的一级质谱的质量精度,计算过程如下图所示:

从计算来看,质量精度均在 10ppm 以内。
其一:说明质谱的分辨率达到较为理想的结果;
其二:说明代谢物鉴定的结果可信度较高;
MS2:二级质谱:
MS2:二级质谱:按照一定的规则进行母离子的选择,再把选择后的母离子进行碰撞打碎后得到的质谱碎片即为该母离子的二级质谱;目前高分辨质谱使用较为常见的母离子选择的规则为 DDA 采集模式,即数据依赖性采集模式,采集规则通常为按照采集到的一级质谱(母离子)的信号强度排列,将 Top N 的一级质谱选择设置进行打碎,再采集其对应的二级质谱碎片,目前二级质谱是高分辨液相色谱质谱进行代谢物鉴定最常用的维度之一,下面给大家展示,标准品的二级质谱图以及样本中代谢物的二级质谱图与数据库匹配的情况:

图 6 | α-亚麻酸的标准品二级质谱图与公共数据库匹配情况

图 7 | 细胞样本中柠檬酸二级质谱图与公共数据库匹配情况
因此,从标准品匹配公共数据库结果来看,质谱(MS1,MS2)匹配度极高,而样本的二级质谱匹配会一定程度上受到基质的干扰,但从鉴定的角度看,适用性和匹配的程度仍较为可靠。
4.鹿明生物代谢组数据鉴定解析技巧—干货分享
基于鹿明生物代谢组平台的数据鉴定技巧分享:
技术平台背景:反相体系下的正负离子模式 DDA 模式分别采集,初始流动相比例为 95% 的高水相,数据采集时间为 16min;
Tip 1:反相体系下,强极性代谢物的保留很弱,基本上在 1min 之前就会出峰,一些极性相对较小的代谢物会在中后段出峰。

图 8 | 数据矩阵-RT 解析
结合化合物的理化性质来看:数据矩阵中的五个代谢物中的很明显异常点在于,反式肉桂酸(trans-Cinnamic acid)属于极性较弱的脂肪酸,应该在高有机相时间段出峰。但是数据矩阵中将其定性鉴定到0.5min左右,因此可将该定性结果归纳为假阳性的结果,暂不使用。
Tip 2:一级质谱(MS1)的匹配情况可以考虑以下三列数据:Mass Error(质量精度),Score(总得分,其中包含一级质谱匹配得分)和 Adducts(离子加和形式)。
Mass Error(质量精度):在搜库定性过程中,已经把范围定在 10ppm 之内,此标准目前通用,因此该项数据可直接使用,不再进行筛选。
Score(总得分,其中包含一级质谱匹配得分):总分 60 分,得分越高,鉴定结果越可靠。
Adducts(离子加和形式):离子加和形式出现种类越多,相对准确度越高;离子加和形式需符合流动相体系。

图 9 | 数据矩阵-MS1 解析
Tip 3:二级质谱(MS2)的匹配情况主要体现在:Fragment Score 二级质谱匹配得分上,该项得分总分 100,得分越高,鉴定结果越可靠。

图 10 | 数据矩阵-MS2 解析
小鹿推荐
代谢组学发展至今,其中一条亟待解决的问题便是代谢物的鉴定、鉴定到代谢物的多少、鉴定的准确度都是我们需要去不断思考学习和发展的内容模块,随着分析化学,结构化学和代谢组学等多学科日益渐增的交流和融合,代谢物鉴定的未来将大有可期。