简介摘要:咖啡休息期间读取映射结果的优化
读取映射是将短序列(也称为“读取”)与参考基因组或从头组装对齐的过程。它几乎是下一代测序(NGS)相关实验(单核苷酸多态性(SNP)调用、RNA序列、芯片序列等)中的一个重要分析步骤,每天都有成千上万的研究人员在进行。
确定正确的区域
作图的主要问题是确定基因组上最有可能产生某一特定阅读的区域。在我攻读博士学位之初,我认为这是一个看似直截了当的问题。然而,考虑到所有可能的基因组变异,以及PCR或测序人工制品,解决重复区域等问题是具有挑战性的。
目前这方面的研究主要集中在加速或减少内存需求上,已经发布了大约100个映射器(对齐读取的程序)。
为了从这个长长的列表中为一个给定的研究选择一个映射器,其他人和我经常依赖口碑推荐、引用次数或一些基准论文。然而,这并不是一个严格的过程,一项研究中使用的绘图器可能不是另一项研究的最佳选择,甚至不是一个好的选择。
此外,选择最佳参数设置比使用最常优化速度的默认设置更有利。如果没有这种优化,重要的snp可能会丢失,基因表达可能会被错误评估,或者可能引入任何其他可能的人工制品。
每次读取都很重要,即使没有映射0.1%的读取也可能导致不准确的结果。然而,通常甚至映射器的开发人员都无法预测给定数据集的最佳参数集。
引子
在我们最近的《基因组生物学》一文中,我介绍了一个新的网站和命令行程序Teaser,它通过自动对标映射程序及其参数设置来解决这些问题。
我的主要动机是快速而简单地评估不同映射程序在数据集上的表现。例如,在咖啡休息时间(大约15分钟)内,可以对人类基因组上的六个不同的映射程序进行基准测试。
在您返回时,将为您提供交互式绘图,根据正确映射的读取百分比及其吞吐量(每秒读取数),可视化每个映射器的执行情况。
此外,Teaser应该易于运行,但仍然可以为每个人调整和定制。这包括实验的生物学条件,如特定的基因组序列和杂合率,以及实验条件,如读取长度或错误率。
列出这些条件后,Teaser可以自动运行任意数量的候选映射器和感兴趣的参数设置。这包括尝试一组参数,例如尝试不同的种子长度,同时更改两个附加参数以增加对齐读取的尝试。
现在,有可能在20分钟内(一杯咖啡加一块饼干)在果蝇黑胃数据集上自动运行34个测试。手工操作会占用学生将近一个月的时间。
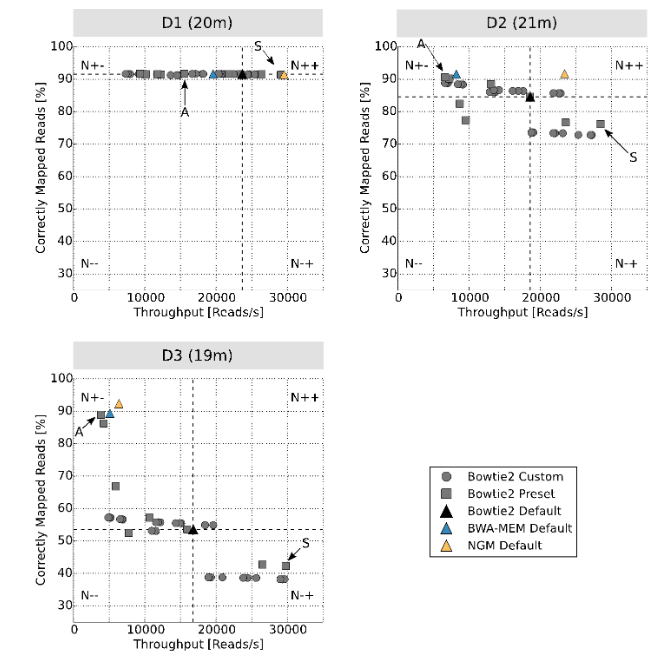
上图显示了结果。您可以从四个区域中选择映射器/参数设置以运行默认参数,例如,Bowtie2:左下(N-)是比默认值差的结果,左上(N+-)是映射率较高但运行时间较长的结果,右下角(N-+)是映射率较低且运行时较低的结果,(N++)是映射率较高且运行时较低的结果。我个人总是根据研究的目标从N+或N++中选择设置。
总而言之,Teaser可以帮助您选择数据的最佳映射器和参数设置。这对每一位投资数千美元来获得测序库的生物学家来说都很重要,现在他们希望尽可能多地利用这些读数。
此外,Teaser可以证明在研究中使用mapper和参数设置是正确的,特别是在分析新的基因组或尝试新的read类型时。此外,Teaser对像我这样的开发人员也很有帮助,因为它简化了新映射程序的基准测试。







