合作专家 | 张冰心博士
农业昆虫害虫防治 中国农业大学

审核专家 | 聂壹峰博士
纳米生物医学 中国科学院大学
简介
原核生物全基因组组装测序已有了较为成熟的方法体系,但是在组装好的基因组注释上还没有较为快捷简便的方法。
Prokka: rapid prokaryotic genome annotation,快速的原核基因组注释,是一个适用于原核生物基因组的快速高效的自动注释工具,以 FASTA 格式的预组装基因组 DNA 序列为输入文件,能够对原核基因组和宏基因组进行快速高效的功能注释,在基因组序列上识别和标记所有相关特征。
用途
原核生物,如细菌的基因组注释,即识别和标记基因组序列上所有相关特征,例如包括预测编码区域及其假定产物以及非编码 RNA,信号肽等。
材料与仪器
组装好之后的细菌基因组 fasta 文件,例如:<filename>.fa
步骤
1. 在 Linux 环境下依赖安装:conda install prokka
2. 激活 环境下的软件:conda activate /path/prokka
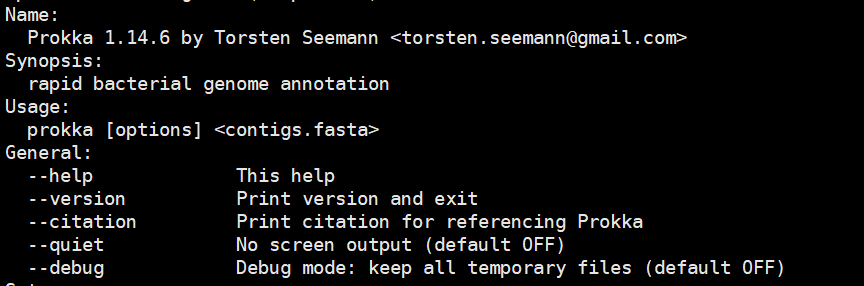
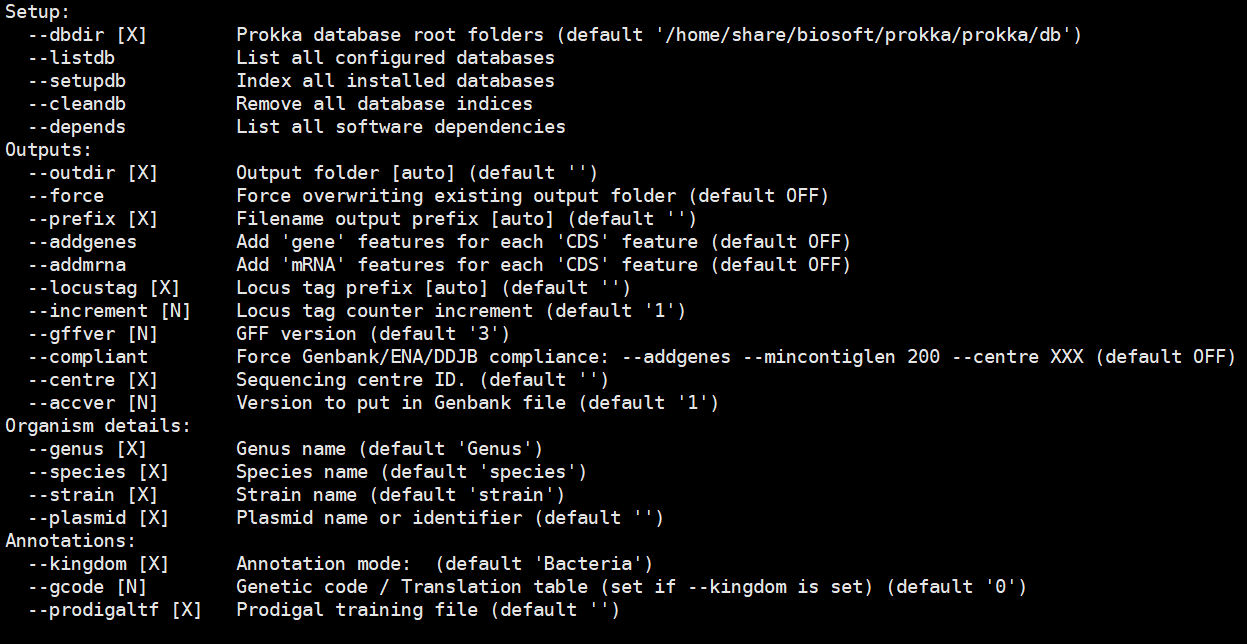
3. 查看参数:prokka -h
4. 运行:
prokka [options] <filename.fasta>
5. 查看结果:
.gff 基因注释文件
.gbk Genebank 格式注释的文件
.fna 输入核苷酸序列文件
.faa 翻译 CDS(编码区)的氨基酸序列
.ffn 所有转录本注释的核苷酸序列
.sqn 用于提交的可编辑格式的序列
.fsa 用于提交的核苷酸序列
.tbl 用于提交的特征表格文件
.err 存疑或错误报告
.log 运行日志
.txt 注释的各种类型序列统计信息
.tsv 所有注释基因特征列表
注意事项
1. 软件前加上原始路径:
![]()
2. 使用前先激活 conda 环境:conda activate path/prokka

3.ftype 默认的是 CDS,使用 addgenes 或 addgmma 参数会区别编码基因或 RNA
来源:丁香实验