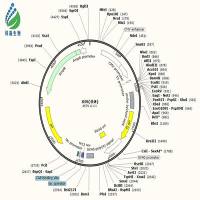
pEGFP-N1质粒图谱及信息
互联网
多克隆位点区
Restriction Map and Multiple Cloning Site of pEGFP-N1. (Unique restriction sites are in color or bold.) The Not I site follows the EGFP stop codon. The Xba I site ~undefined) is methylated in the DNA provided by CLONTECH. If you wish to digest the vector with this enzyme, you will need to transform the vector into a dam- host and make fresh DNA.
Description
pEGFP-N1 encodes a red-shifted variant of wild-type GFP (1-3) which has been optimized for brighter fluorescence and higher expression in mammalian cells. (Excitation maximum = 488 nm; emission maximum = 507 nm.) pEGFP-N1 encodes the GFPmut1 variant (4) which contains the double-amino-acid substitution of Phe-64 to Leu and Ser-65 to Thr. The coding sequence of the EGFP gene contains more than 190 silent base changes which correspond to human codon-usage preferences (5). Sequences flanking EGFP have been converted to a Kozak consensus translation initiation site (6) to further increase the translation efficiency in eukaryotic cells. The MCS in pEGFP-N1 is between the immediate early promoter of CMV (PCMV IE ) and the EGFP coding sequences. Genes cloned into the MCS will be expressed as fusions to the N-terminus of EGFP if they are in the same reading frame as EGFP and there are no intervening stop codons. SV40 polyadenylation signals downstream of the EGFP gene direct proper processing of the 3' end of the EGFP mRNA. The vector backbone also contains an SV40 origin for replication in mammalian cells expressing the SV40 T-antigen. A neomycin-resistance cassette (neor ), consisting of the SV40 early promoter, the neomycin/kanamycin resistance gene of Tn5, and polyadenylation signals from the Herpes simplex thymidine kinase gene, allows stably transfected eukaryotic cells to be selected using G418. A bacterial promoter upstream of this cassette (Pamp ) expresses kanamycin resistance in E. coli . The pEGFP-N1 backbone also provides a pUC19 origin of replication for propagation in E. coli and an f1 origin for single-stranded DNA production.
Use
Fusions to the N-terminus of EGFP retain the fluorescent properties of the native protein allowing the localization of the fusion protein in vivo . The target gene should be cloned into pEGFP-N1 so that it is in frame with the EGFP coding sequences, with no intervening in-frame stop codons. The inserted gene should include the initiating ATG codon. The recombinant EGFP vector can be transfected into mammalian cells using any standard transfection method. If required, stable transformants can be selected using G418 (7). pEGFP-N1 can also be used simply to express EGFP in a cell line of interest (e.g., as a transfection marker).
Feature Locations
-
Human cytomegalovirus (CMV) immediate early promoter: 1-589
- Enhancer region: 59-465
- TATA box: 554-560
- Transcription start point: 583
- C-> G mutation to remove Sac I site: 569
- MCS: 591-671
-
Enhanced green fluorescent protein gene
- Kozak consensus translation initiation site: 672-682
- Start codon (ATG): 679-681; Stop codon: 1396-1398
- Insertion of Val at position 2: 682-684
- GFPmut1 chromophore mutations (Phe-64 to Leu; Ser-65 to Thr): 871-876
- His-231 to Leu mutation (AÆ T): 1373
-
SV40 early mRNA polyadenylation signal
- Polyadenylation signals: 1552-1557 & 1581-1586
- mRNA 3' ends: 1590 & 1602
-
f1 single-strand DNA origin: 1649-2104
(packages the noncoding strand of EGFP) -
Bacterial promoter expression of Kanr gene:
- -35 region: 2166-2171; -10 region: 2189-2194
- Transcription start point: 2201
- SV40 origin of replication: 2445-2580
-
SV40 early promoter
- Enhancer (72-bp tandem repeats): 2278-2349 & 2350-2421
- 21-bp repeats: 2425-2445, 2446-2466, & 2468-2488
- Early promoter element: 2501-2507
- Major transcription start points: 2497, 2535, 2541 & 2546
-
Kanamycin/neomycin resistance gene
- Neomycin phosphotransferase coding sequences:
- Start codon (ATG): 2629-2631; stop codon: 3421-3423
- G-> A mutation to remove Pst I site: 2811
- C-> A (Arg to Ser) mutation to remove Bss H II site: 3157
-
Herpes simplex virus (HSV) thymidine kinase (TK) polyadenylation signal
Polyadenylation signals: 3659-3664 & 3672-3677 pUC plasmid replication origin: 4008-4651
Primer Sites
- EGFP-N Sequencing Primer (#6479-1): 745-724
- EGFP-C Sequencing Primer (#6478-1): 1332-1353
Sequence (text)
Sequence (pdf)
Restriction Digest (pdf)
全序列:
TAGTTATTAA TAGTAATCAA TTACGGGGTC ATTAGTTCAT AGCCCATATA TGGAGTTCCG CGTTACATAA CTTACGGTAA ATGGCCCGCC TGGCTGACCG CCCAACGACC CCCGCCCATT GACGTCAATA ATGACGTATG TTCCCATAGT AACGCCAATA GGGACTTTCC ATTGACGTCA ATGGGTGGAG TATTTACGGT AAACTGCCCA CTTGGCAGTA CATCAAGTGT ATCATATGCC AAGTACGCCC CCTATTGACG TCAATGACGG TAAATGGCCC GCCTGGCATT ATGCCCAGTA CATGACCTTA TGGGACTTTC CTACTTGGCA GTACATCTAC GTATTAGTCA TCGCTATTAC CATGGTGATG CGGTTTTGGC AGTACATCAA TGGGCGTGGA TAGCGGTTTG ACTCACGGGG ATTTCCAAGT CTCCACCCCA TTGACGTCAA TGGGAGTTTG TTTTGGCACC AAAATCAACG GGACTTTCCA AAATGTCGTA ACAACTCCGC CCCATTGACG CAAATGGGCG GTAGGCGTGT ACGGTGGGAG GTCTATATAA GCAGAGCTGG TTTAGTGAAC CGTCAGATCC GCTAGCGCTA CCGGACTCAG ATCTCGAGCT CAAGCTTCGA ATTCTGCAGT CGACGGTACC GCGGGCCCGG GATCCACCGG TCGCCACCAT GGTGAGCAAG GGCGAGGAGC TGTTCACCGG GGTGGTGCCC ATCCTGGTCG AGCTGGACGG CGACGTAAAC GGCCACAAGT TCAGCGTGTC CGGCGAGGGC GAGGGCGATG CCACCTACGG CAAGCTGACC CTGAAGTTCA TCTGCACCAC CGGCAAGCTG CCCGTGCCCT GGCCCACCCT CGTGACCACC CTGACCTACG GCGTGCAGTG CTTCAGCCGC TACCCCGACC ACATGAAGCA GCACGACTTC TTCAAGTCCG CCATGCCCGA AGGCTACGTC CAGGAGCGCA CCATCTTCTT CAAGGACGAC GGCAACTACA AGACCCGCGC CGAGGTGAAG TTCGAGGGCG ACACCCTGGT GAACCGCATC GAGCTGAAGG GCATCGACTT CAAGGAGGAC GGCAACATCC TGGGGCACAA GCTGGAGTAC AACTACAACA GCCACAACGT CTATATCATG GCCGACAAGC AGAAGAACGG CATCAAGGTG AACTTCAAGA TCCGCCACAA CATCGAGGAC GGCAGCGTGC AGCTCGCCGA CCACTACCAG CAGAACACCC CCATCGGCGA CGGCCCCGTG CTGCTGCCCG ACAACCACTA CCTGAGCACC CAGTCCGCCC TGAGCAAAGA CCCCAACGAG AAGCGCGATC ACATGGTCCT GCTGGAGTTC GTGACCGCCG CCGGGATCAC TCTCGGCATG GACGAGCTGT ACAAGTAAAG CGGCCGCGAC TCTAGATCAT AATCAGCCAT ACCACATTTG TAGAGGTTTT ACTTGCTTTA AAAAACCTCC CACACCTCCC CCTGAACCTG AAACATAAAA TGAATGCAAT TGTTGTTGTT AACTTGTTTA TTGCAGCTTA TAATGGTTAC AAATAAAGCA ATAGCATCAC AAATTTCACA AATAAAGCAT TTTTTTCACT GCATTCTAGT TGTGGTTTGT CCAAACTCAT CAATGTATCT TAAGGCGTAA ATTGTAAGCG TTAATATTTT GTTAAAATTC GCGTTAAATT TTTGTTAAAT CAGCTCATTT TTTAACCAAT AGGCCGAAAT CGGCAAAATC CCTTATAAAT CAAAAGAATA GACCGAGATA GGGTTGAGTG TTGTTCCAGT TTGGAACAAG AGTCCACTAT TAAAGAACGT GGACTCCAAC GTCAAAGGGC GAAAAACCGT CTATCAGGGC GATGGCCCAC TACGTGAACC ATCACCCTAA TCAAGTTTTT TGGGGTCGAG GTGCCGTAAA GCACTAAATC GGAACCCTAA AGGGAGCCCC CGATTTAGAG CTTGACGGGG AAAGCCGGCG AACGTGGCGA GAAAGGAAGG GAAGAAAGCG AAAGGAGCGG GCGCTAGGGC GCTGGCAAGT GTAGCGGTCA CGCTGCGCGT AACCACCACA CCCGCCGCGC TTAATGCGCC GCTACAGGGC GCGTCAGGTG GCACTTTTCG GGGAAATGTG CGCGGAACCC CTATTTGTTT ATTTTTCTAA ATACATTCAA ATATGTATCC GCTCATGAGA CAATAACCCT GATAAATGCT TCAATAATAT TGAAAAAGGA AGAGTCCTGA GGCGGAAAGA ACCAGCTGTG GAATGTGTGT CAGTTAGGGT GTGGAAAGTC CCCAGGCTCC CCAGCAGGCA GAAGTATGCA AAGCATGCAT CTCAATTAGT CAGCAACCAG GTGTGGAAAG TCCCCAGGCT CCCCAGCAGG CAGAAGTATG CAAAGCATGC ATCTCAATTA GTCAGCAACC ATAGTCCCGC CCCTAACTCC GCCCATCCCG CCCCTAACTC CGCCCAGTTC CGCCCATTCT CCGCCCCATG GCTGACTAAT TTTTTTTATT TATGCAGAGG CCGAGGCCGC CTCGGCCTCT GAGCTATTCC AGAAGTAGTG AGGAGGCTTT TTTGGAGGCC TAGGCTTTTG CAAAGATCGA TCAAGAGACA GGATGAGGAT CGTTTCGCAT GATTGAACAA GATGGATTGC ACGCAGGTTC TCCGGCCGCT TGGGTGGAGA GGCTATTCGG CTATGACTGG GCACAACAGA CAATCGGCTG CTCTGATGCC GCCGTGTTCC GGCTGTCAGC GCAGGGGCGC CCGGTTCTTT TTGTCAAGAC CGACCTGTCC GGTGCCCTGA ATGAACTGCA AGACGAGGCA GCGCGGCTAT CGTGGCTGGC CACGACGGGC GTTCCTTGCG CAGCTGTGCT CGACGTTGTC ACTGAAGCGG GAAGGGACTG GCTGCTATTG GGCGAAGTGC CGGGGCAGGA TCTCCTGTCA TCTCACCTTG CTCCTGCCGA GAAAGTATCC ATCATGGCTG ATGCAATGCG GCGGCTGCAT ACGCTTGATC CGGCTACCTG CCCATTCGAC CACCAAGCGA AACATCGCAT CGAGCGAGCA CGTACTCGGA TGGAAGCCGG TCTTGTCGAT CAGGATGATC TGGACGAAGA GCATCAGGGG CTCGCGCCAG CCGAACTGTT CGCCAGGCTC AAGGCGAGCA TGCCCGACGG CGAGGATCTC GTCGTGACCC ATGGCGATGC CTGCTTGCCG AATATCATGG TGGAAAATGG CCGCTTTTCT GGATTCATCG ACTGTGGCCG GCTGGGTGTG GCGGACCGCT ATCAGGACAT AGCGTTGGCT ACCCGTGATA TTGCTGAAGA GCTTGGCGGC GAATGGGCTG ACCGCTTCCT CGTGCTTTAC GGTATCGCCG CTCCCGATTC GCAGCGCATC GCCTTCTATC GCCTTCTTGA CGAGTTCTTC TGAGCGGGAC TCTGGGGTTC GAAATGACCG ACCAAGCGAC GCCCAACCTG CCATCACGAG ATTTCGATTC CACCGCCGCC TTCTATGAAA GGTTGGGCTT CGGAATCGTT TTCCGGGACG CCGGCTGGAT GATCCTCCAG CGCGGGGATC TCATGCTGGA GTTCTTCGCC CACCCTAGGG GGAGGCTAAC TGAAACACGG AAGGAGACAA TACCGGAAGG AACCCGCGCT ATGACGGCAA TAAAAAGACA GAATAAAACG CACGGTGTTG GGTCGTTTGT TCATAAACGC GGGGTTCGGT CCCAGGGCTG GCACTCTGTC GATACCCCAC CGAGACCCCA TTGGGGCCAA TACGCCCGCG TTTCTTCCTT TTCCCCACCC CACCCCCCAA GTTCGGGTGA AGGCCCAGGG CTCGCAGCCA ACGTCGGGGC GGCAGGCCCT GCCATAGCCT CAGGTTACTC ATATATACTT TAGATTGATT TAAAACTTCA TTTTTAATTT AAAAGGATCT AGGTGAAGAT CCTTTTTGAT AATCTCATGA CCAAAATCCC TTAACGTGAG TTTTCGTTCC ACTGAGCGTC AGACCCCGTA GAAAAGATCA AAGGATCTTC TTGAGATCCT TTTTTTCTGC GCGTAATCTG CTGCTTGCAA ACAAAAAAAC CACCGCTACC AGCGGTGGTT TGTTTGCCGG ATCAAGAGCT ACCAACTCTT TTTCCGAAGG TAACTGGCTT CAGCAGAGCG CAGATACCAA ATACTGTCCT TCTAGTGTAG CCGTAGTTAG GCCACCACTT CAAGAACTCT GTAGCACCGC CTACATACCT CGCTCTGCTA ATCCTGTTAC CAGTGGCTGC TGCCAGTGGC GATAAGTCGT GTCTTACCGG GTTGGACTCA AGACGATAGT TACCGGATAA GGCGCAGCGG TCGGGCTGAA CGGGGGGTTC GTGCACACAG CCCAGCTTGG AGCGAACGAC CTACACCGAA CTGAGATACC TACAGCGTGA GCTATGAGAA AGCGCCACGC TTCCCGAAGG GAGAAAGGCG GACAGGTATC CGGTAAGCGG CAGGGTCGGA ACAGGAGAGC GCACGAGGGA GCTTCCAGGG GGAAACGCCT GGTATCTTTA TAGTCCTGTC GGGTTTCGCC ACCTCTGACT TGAGCGTCGA TTTTTGTGAT GCTCGTCAGG GGGGCGGAGC CTATGGAAAA ACGCCAGCAA CGCGGCCTTT TTACGGTTCC TGGCCTTTTG CTGGCCTTTT GCTCACATGT TCTTTCCTGC GTTATCCCCT GATTCTGTGG ATAACCGTAT TACCGCCATG CAT