聊聊什么是蛋白组学,侃侃它的研究方法
吉凯
最简化的中心法则是 DNA 经过转录成为 RNA,RNA 经过翻译成为蛋白质,由于蛋白质组学(简称蛋白组)关心的是翻译成为蛋白质后发生的事情,因此这里就不赘述诸如逆转录,转录后调控等过程了。
研究什么
那么蛋白组究竟研究的是什么呢?
简单的说呢,就是高通量或者说大规模地研究蛋白质的科学。具体来说主要是三大块:
-
第一,蛋白质定性,或者说大规模检测某些蛋白质是否存在于样品当中;
-
第二,蛋白质定量,也就是大规模检测某些蛋白质的含量(包括绝对含量与相对含量);
-
第三,蛋白质翻译后修饰,这些修饰主要包括磷酸化,泛素化,糖基化,乙酰化等等,也包括对这些翻译后修饰的定量研究。
这三大块中所提到的大规模,既可以是样品数量的大规模高通量,也可以是少量样本中蛋白数量的大规模高通量。
研究原因
有的同学可能又要问,简单的定性定量研究,有了 RNA-seq 等高通量的实验方法,为什么还学要蛋白组学呢?
首先,由于翻译调控和翻译后调控的存在,RNA 的表达量与实际对应蛋白质的含量相关性并不高,1999 年, 蛋白组学界大神 Steven Gygi 还在另一位大神 Ruedi Aebersold 门下学习时发表的古老文章,就简单地测试了酵母中 mRNA 和对应蛋白质的定量相关性,结果是,低丰度蛋白与 mRNA 的相关性尤其低,而高丰度蛋白和其 mRNA 的相关性则高,经过平均后 r 值仅为 0.4。
那么,低丰度蛋白都指的是什么呢?
诸如蛋白激酶,转录因子等调控性蛋白大多都是低丰度蛋白,这些可都是做学术的各位最为青睐的蛋白呀。当然,这篇文章年代久远,蛋白与 mRNA 相关性的讨论在学术界依然激烈,相当大一部分文章也依然使用 mRNA 来代表蛋白含量,但是,由此我们也可以知道,如果想要精细了解一个蛋白质的定量信息,直接观察蛋白质本身才是最为靠谱的方案。
其次,很多蛋白质的功能和调控与其翻译后修饰密不可分,例如,有的蛋白质需要磷酸化后才能行使功能,有的蛋白质会在特定条件下经过泛素化降解,从而通过调节其丰度而调节其在细胞内功能,这两篇文章都是我所待过的实验室的研究成果,一篇是讲植物光信号的转导,一篇是讲人体铁内稳态的调控,由此也可以知道,蛋白质翻译后修饰对于从植物到动物都起着非常重要的作用,那么了解它们定性定量信息的重要性就不言而喻了。
如何研究
说了这么多,我们究竟怎么研究蛋白质组学呢?
大概分为两类,基于抗体免疫的方法,和基于质谱学的方法。
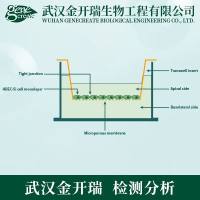
抗体免疫的方法呢,其实就是 ELISA,Western 及蛋白质芯片。通过合成大量蛋白质特异的抗体,能够进行定性检测及相对定量分析,只要你有好用的抗体,那么就可以通过免疫反应让抗体快速的识别你感兴趣的蛋白质,然后用例如 HRP 发光等标记方法显示它们是否存在于你的样品当中。现在已有的抗体不仅能识别特定蛋白质,还能识别特定修饰的特定蛋白质或者被特定修饰过的特定蛋白质 Motif。
基于抗体的方法呢,好处是速度快,特异性好,灵敏度也相对高,坏处呢,是通量低,价格高……有人可能会说有蛋白质芯片呀,我个人非常怀疑蛋白质芯片里究竟有多少抗体是特异性好且效价高的。
目前高通量检测蛋白质的方法中,还是首推基于质谱的方法,纳流液相可以将复杂样品中的肽段高效地分离,然后依次进入质谱,对每个被离子化的肽段及其碎裂后碎片的荷质比进行分析,从而得到该肽段的序列信息,然后根据对应的色谱峰面积或者报告离子强度等信息,我们又可以得到该肽段的定量信息。
综上所述呢,基于质谱的方法呢,不仅一次性告诉你,你的样品里都有哪些蛋白质,蛋白质都有多少,还能告诉你它们带没带翻译后修饰,修饰在哪个氨基酸上面,这种修饰的蛋白有多少。
随着质谱仪器与检测方式的进步,对于样品信息的覆盖率以及低丰度蛋白的灵敏度,正在快速提高。
那么到底有多高呢,2014 和 2015 年人类蛋白组图谱的两篇报道,通过多组织样品全蛋白组分析,已经可以从推测的 2 万多个可编码蛋白中做到了 90% 的覆盖,而当时的仪器条件来说,单次 60 分钟梯度,也就检测出约 1000 个蛋白质,如今对于癌细胞,一次 60 分钟的梯度可以达到约 4000 个蛋白质的水平甚至更多。
对于可以解决的科学问题,蛋白组学与传统免疫沉淀等生化方法联用,可以一次找出目标蛋白的多个相互作用蛋白,蛋白组学与交联及冷冻电镜联用可以得到蛋白复合体的结构信息,可以进行绝对定量用于临床检测等等。