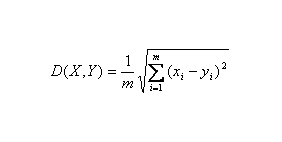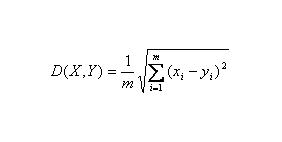聚类分析
互联网
1396
聚类通过把目标数据放入少数相对同源的组或“类”(cluster)里。分析表达数据,(1)通过一系列的检测将待测的一组基因的变异标准化,然后成对比较线性协方差。(2)通过把用最紧密关联的谱来放基因进行样本聚类,例如用简单的层级聚类(hierarchical clustering)方法。这种聚类亦可扩展到每个实验样本,利用一组基因总的线性相关进行聚类。(3)多维等级分析(multidimensional scaling analysis,MDS)是一种在二维Euclidean “距离”中显示实验样本相关的大约程度。(4)K-means方法聚类,通过重复再分配类成员来使“类”内分散度最小化的方法。
聚类方法有两个显著的局限:首先,要聚类结果要明确就需分离度很好(well-separated)的数据。几乎所有现存的算法都是从互相区别的不重叠的类数据中产生同样的聚类。但是,如果类是扩散且互相渗透,那么每种算法的的结果将有点不同。结果,每种算法界定的边界不清,每种聚类算法得到各自的最适结果,每个数据部分将产生单一的信息。为解释因不同算法使同样数据产生不同结果,必须注意判断不同的方式。对遗传学家来说,正确解释来自任一算法的聚类内容的实际结果是困难的(特别是边界)。最终,将需要经验可信度通过序列比较来指导聚类解释。
第二个局限由线性相关产生。上述的所有聚类方法分析的仅是简单的一对一的关系。因为只是成对的线性比较,大大减少发现表达类型关系的计算量,但忽视了生物系统多因素和非线性的特点。