知道这些套路,导师再也不用担心我不会统计学了
丁香园
很多朋友跟我说统计学很难,其实这个东西你说难也难,说简单也简单。简单是因为只需要知道自己的统计资料是什么类型,把数据导入 SPSS 然后找到对应的分析方法就行了,分分钟出结果;难是因为里面各种资料的分类,数据的录入,软件的操作,以及模型的建造难。
统计学是门工具,既然是个工具肯定得让人们能学会使用,所以必有一些套路和捷径。就像 CS(计算机科学),IT,没有专业学过的都知道很难吧,但是让你用电脑查个资料,用个软件总会吧?
所以统计学简单。而且我们科研狗不需要掌握像国家统计局工作人员那样深的统计学知识,我们只需要什么样的资料用哪种统计学方法分析就可以了,然后再用 SPSS 软件操作就行了(后面我可能开视频课来讲 SPSS 的具体操作,绝对通俗易懂,一学就会)。既然有套路,我就带大家看看统计学都有哪些套路:
<1>
首先,要科普一下基本知识,基本知识都不懂, 怎么学统计学?
自变量(Independent variable):自变量是指研究者主动操纵,而引起因变量发生变化的因素或条件,因此自变量被看作是因变量的原因。
因变量(Dependent variable):实验中由于自变量而引起实验对象的变化和结果叫做因变量。
咳咳,划重点了:O(∩_∩)O:很多人容易搞混这两个概念,因为这两个定义是翻译过来的,我个人觉得不准确也不好理解,我觉得自变量应该翻译为独立变量,就从字面上硬翻,而自变量翻译为因此变量。
计数资料:指先将观察单位按其性质或类别分组,然后清点各组观察单位个数所得的资料。其特点是: 对每组观察单位只研究其数量的多少,而不具体考虑某指标的质量特征,属非连续性资料。
计量资料:指先将观察单位按其性质或类别分组,然后清点各组观察单位个数所得的资料。其特点是: 对每组观察单位只研究其数量的多少,而不具体考虑某指标的质量特征,属非连续性资料。
我们观察或者测量因变量得到的数据集合就是统计资料,医学统计资料按其性质一般分为计数资料与计量资料两类。
为什么要分成两种资料呢?因为不同类型的统计资料应采用不同的统计分析方法。
为什么不同资料要用不同的统计学分析方法呢?因为统计分析方法相当于一个比较两个东西之间差异(或差距)的平台。
比如苹果,橙子,那我想知道苹果,橙子之间的不同,那我可以从重量,形态,体积大小,颜色,甜度,口感,种属关系等不同角度去测量然后得到数据(也就是统计学资料),重量可以测量(得到计量资料),然后我们就可以用独立样本的 t 检验分析得出苹果跟橙子在重量上是有差异的也就是这两种水果是不同的。
但我们只知道苹果跟橙子在重量上有差异是不够的,假如一个橙子跟苹果的重量相等的话,我们就不能说橙子是苹果吧,于是我们要进一步了解和认识到苹果和橙子的确是不同的,怎么办呢?
人类是很聪明的,自然就想到了办法,人们会给它分类,然后计算个数,比如颜色,苹果一般为红色,橙子一般为黄色,所以我们可以测这两种水果的颜色的个数,我们得到数据资料(就是计数资料)。
最后所有重量,形态,体积大小,颜色,甜度,口感,种属关系等的资料统计在一起,建造一个模型,我们简称为苹果-橙子模型。然后用 logistic 回归分析,分析得到苹果跟橙子是不同的。
以后我们只需要输入一个物体 x 的参数,如把重量,形态,体积大小,颜色,甜度,口感,种属关系等数据输入进去得到结果,然后概率学角度来判断物体x是橙子还是苹果或者两者都不是。
说这么多就是想让大家知道统计学就是一个分析工具,根据不同资料的情况,我们分析数据的方法也就不同。
上个图大家就明白了,不同资料选择不同分析方法。
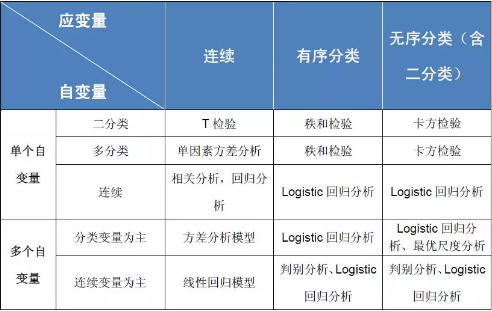
<2>
接下来我就教大家具体怎样选择统计分析方法:
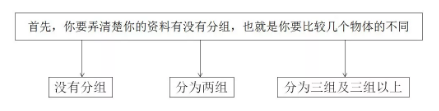
不知道自己的实验设计是如何分组的,请自行解决。
<3>
知道了自己的实验分组就好办了。接下来的三张图就教大家怎样按图索骥,选择适合的统计分析方法来分析自己的数据有没有统计学意义了。
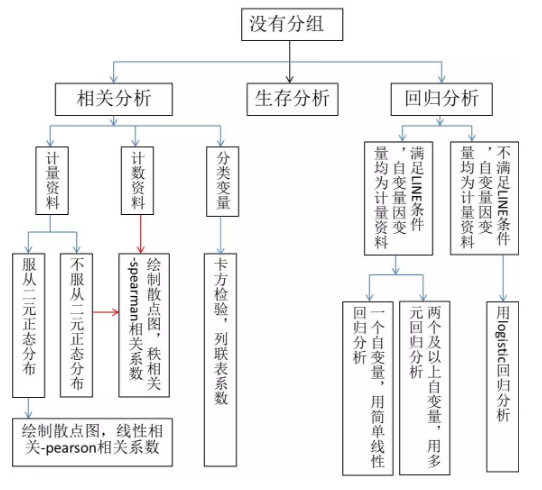
注:线性回归需满足 LINE 条件
L(Linear):因变量与自变量呈线性关系;
I(Independent):每个个体观察值之间互相独立;
N(Normal distribution):在一定范围内,任意给定 X 值,对应的随机变量 Y 都服从正态分布;
E(Equal variance):在一定范围内,不同的 X 值所对应的随机变量 Y 的方差相等;
<4>
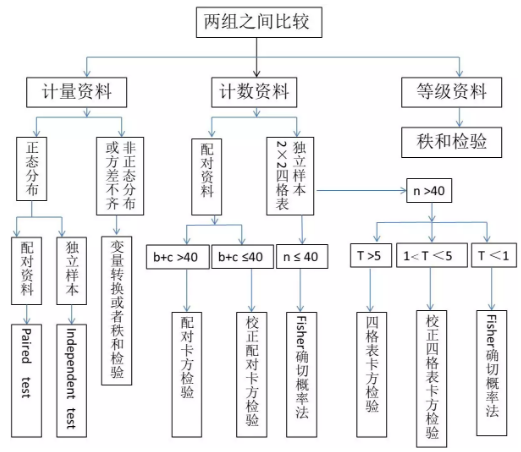
注:两组之间比较是最常见的,一个处理组,一个对照组,自变量经处理因素处理之后产生因变量,然后统计因变量数据,再根据因变量数据的不同类型,选择不同的统计方法比较两组之间是否因变量有差异。
<5>
但有时候我们的实验会分为三组,如按不同时间,不同浓度,不同剂量等,这时候我们要比较这些分组的数据,我们就得用三组及三组以上的统计学方法来分析组间的差异。
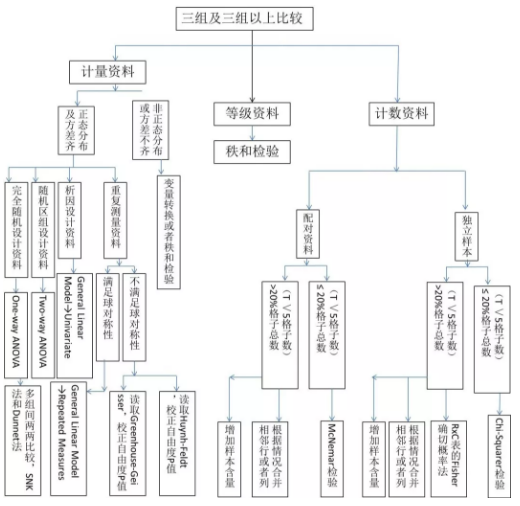
随机区组设计资料 | 性质相近为一个区组,每个区组内对象随机接受不同处理措施 |
析因设计 | 多个实验因素不同水平组合,分析单独效应,交互效应,确定主效应 |
重复测量资料 | 同一受试对象的同一观察指标在不同时间点上进行多次测量的资料 |
注:随机区组设计资料与重复测量资料区别:
1.重复测量资料中同一受试对象的数据具有相关性;
2.重复测量资料中处理因素在受试对象间随机分配,各时间点上固定;随机区组资料中处理因素在区组内随机分配;
相信大家看了以上图片就知道统计学的套路原来是如此简单。大家只需要按图索骥就行了。至于怎么用 SPSS 做统计学分析,大家可以在百度上搜索教程。
举个例子:
<6>
写在后面:笔者目前为止用上面 4 张图基本上可以解决统计学的问题了,当然统计学还有更深入的内容,但我想如果需要做到那一步了,大家还是会去请专业人士帮忙做统计分析的。人的精力有限,擅长的专业也有所不同。
另外,很多小伙伴有个误区:就是觉得统计学能拯救他们的实验结果以及实验方案,其实并不是的,你的实验方案定了,你的统计学分析方法就定了,然后统计学只是帮你分析你的实验数据有没有差异而已。
另外实验数据没有差异,大家会想到修改数据,这里的话不建议大家这样做。建议大家先做预实验,预实验结果有统计学意义,后面重复即可;预实验数据没有意义,大家可以增加剂量或者浓度,使其达到有统计学意义,如果还达不到统计学意义,可以修改方案或者路线了。
为什么要这样做呢?因为这样才没有违背实验的初衷啊,再说修改数据就已经是造假了,前段时间国内一些知名院校的文章相继被撤稿 107 余篇,这着实令国人羞愧啊。大家都是搞科研的,也知道科学这一领域其实也是造不了假的,真相迟早会大白的。这也正是科研的纯净和美之所在,不是吗?
不说了,我去做实验了。





